
-
1. Erste Schritte
- 1.1 Über Versionskontrolle
- 1.2 Eine kurze Geschichte von Git
- 1.3 Was ist Git?
- 1.4 Die Kommandozeile
- 1.5 Git installieren
- 1.6 Erstmalige Git-Einrichtung
- 1.7 Hilfe bekommen
- 1.8 Zusammenfassung
-
2. Git Grundlagen
-
3. Git Branching
- 3.1 Branches im Überblick
- 3.2 Grundlegendes Branching und Merging
- 3.3 Branch-Management
- 3.4 Branching-Workflows
- 3.5 Remote-Branches
- 3.6 Rebasing
- 3.7 Zusammenfassung
-
4. Git auf dem Server
- 4.1 Die Protokolle
- 4.2 Git auf einem Server einrichten
- 4.3 Generieren Ihres SSH-Public-Keys
- 4.4 Einrichten des Servers
- 4.5 Git Daemon
- 4.6 Smart HTTP
- 4.7 GitWeb
- 4.8 GitLab
- 4.9 Drittanbieter-Hosting-Optionen
- 4.10 Zusammenfassung
-
5. Verteiltes Git
-
6. GitHub
-
7. Git-Werkzeuge
- 7.1 Revisionsauswahl
- 7.2 Interaktives Staging
- 7.3 Stashing und Bereinigen
- 7.4 Ihre Arbeit signieren
- 7.5 Suchen
- 7.6 Historie umschreiben
- 7.7 Reset entmystifiziert
- 7.8 Fortgeschrittenes Merging
- 7.9 Rerere
- 7.10 Debugging mit Git
- 7.11 Submodule
- 7.12 Bundling
- 7.13 Ersetzen
- 7.14 Credential-Speicher
- 7.15 Zusammenfassung
-
8. Git anpassen
-
9. Git und andere Systeme
- 9.1 Git als Client
- 9.2 Migration zu Git
- 9.3 Zusammenfassung
-
10. Git-Interna
- 10.1 Plumbing und Porcelain
- 10.2 Git-Objekte
- 10.3 Git-Referenzen
- 10.4 Packfiles
- 10.5 Die Refspec
- 10.6 Übertragungsprotokolle
- 10.7 Wartung und Datenwiederherstellung
- 10.8 Umgebungsvariablen
- 10.9 Zusammenfassung
-
Anhang A: Git in anderen Umgebungen
- A1.1 Grafische Oberflächen
- A1.2 Git in Visual Studio
- A1.3 Git in Visual Studio Code
- A1.4 Git in IntelliJ / PyCharm / WebStorm / PhpStorm / RubyMine
- A1.5 Git in Sublime Text
- A1.6 Git in Bash
- A1.7 Git in Zsh
- A1.8 Git in PowerShell
- A1.9 Zusammenfassung
-
Anhang B: Git in Ihre Anwendungen einbetten
- A2.1 Kommandozeilen-Git
- A2.2 Libgit2
- A2.3 JGit
- A2.4 go-git
- A2.5 Dulwich
-
Anhang C: Git-Befehle
- A3.1 Einrichtung und Konfiguration
- A3.2 Projekte abrufen und erstellen
- A3.3 Grundlegendes Snapshotting
- A3.4 Branching und Merging
- A3.5 Projekte teilen und aktualisieren
- A3.6 Inspektion und Vergleich
- A3.7 Debugging
- A3.8 Patching
- A3.9 E-Mail
- A3.10 Externe Systeme
- A3.11 Administration
- A3.12 Plumbing-Befehle
5.2 Distributed Git - Mitarbeit an einem Projekt
Mitarbeit an einem Projekt
Die Hauptschwierigkeit bei der Beschreibung, wie man zu einem Projekt beiträgt, liegt in den zahlreichen Variationen, wie dies geschehen kann. Da Git sehr flexibel ist, können und arbeiten Menschen auf vielfältige Weise zusammen, und es ist problematisch zu beschreiben, wie Sie beitragen sollten – jedes Projekt ist etwas anders. Einige der beteiligten Variablen sind die Anzahl der aktiven Mitwirkenden, der gewählte Workflow, Ihr Commit-Zugriff und möglicherweise die externe Beitragsmethode.
Die erste Variable ist die Anzahl der aktiven Mitwirkenden – wie viele Benutzer tragen aktiv Code zu diesem Projekt bei und wie oft? In vielen Fällen werden Sie zwei oder drei Entwickler mit einigen Commits pro Tag haben, oder möglicherweise weniger bei eher ruhenden Projekten. Für größere Unternehmen oder Projekte kann die Anzahl der Entwickler Tausende betragen, mit Hunderten oder Tausenden von Commits, die täglich eingehen. Dies ist wichtig, denn mit immer mehr Entwicklern treten mehr Probleme auf, wenn sichergestellt werden muss, dass Ihr Code sauber angewendet wird oder leicht zusammengeführt werden kann. Änderungen, die Sie einreichen, können durch Arbeiten, die zusammengeführt werden, während Sie gearbeitet haben oder während Ihre Änderungen auf Genehmigung oder Anwendung warteten, obsolet oder stark beschädigt werden. Wie können Sie Ihren Code konsistent auf dem neuesten Stand halten und Ihre Commits gültig machen?
Die nächste Variable ist der verwendete Workflow für das Projekt. Ist er zentralisiert, wobei jeder Entwickler den gleichen Schreibzugriff auf die Hauptcodelinie hat? Hat das Projekt einen Maintainer oder Integrationsmanager, der alle Patches prüft? Werden alle Patches von Peers überprüft und genehmigt? Sind Sie an diesem Prozess beteiligt? Gibt es ein Leutnantensystem, und müssen Sie Ihre Arbeit zuerst an sie einreichen?
Die nächste Variable ist Ihr Commit-Zugriff. Der Workflow, der erforderlich ist, um zu einem Projekt beizutragen, unterscheidet sich erheblich, wenn Sie Schreibzugriff auf das Projekt haben oder nicht. Wenn Sie keinen Schreibzugriff haben, wie akzeptiert das Projekt bevorzugt beigesteuerte Arbeit? Hat es überhaupt eine Richtlinie? Wie viel Arbeit tragen Sie jeweils bei? Wie oft tragen Sie bei?
Alle diese Fragen können beeinflussen, wie Sie effektiv zu einem Projekt beitragen und welche Workflows bevorzugt oder Ihnen zur Verfügung stehen. Wir werden Aspekte jedes dieser Punkte in einer Reihe von Anwendungsfällen behandeln, von einfachen bis zu komplexeren; Sie sollten in der Lage sein, die spezifischen Workflows, die Sie in der Praxis benötigen, aus diesen Beispielen zu konstruieren.
Commit-Richtlinien
Bevor wir uns mit den spezifischen Anwendungsfällen befassen, hier ein kurzer Hinweis zu Commit-Nachrichten. Gute Richtlinien für die Erstellung von Commits und deren Einhaltung machen die Arbeit mit Git und die Zusammenarbeit mit anderen erheblich einfacher. Das Git-Projekt stellt ein Dokument zur Verfügung, das eine Reihe guter Tipps zur Erstellung von Commits für die Einreichung von Patches enthält – Sie können es im Git-Quellcode in der Datei Documentation/SubmittingPatches lesen.
Erstens sollten Ihre Einreichungen keine Whitespace-Fehler enthalten. Git bietet eine einfache Möglichkeit, dies zu überprüfen – führen Sie vor dem Commit git diff --check aus, der mögliche Whitespace-Fehler identifiziert und Ihnen auflistet.
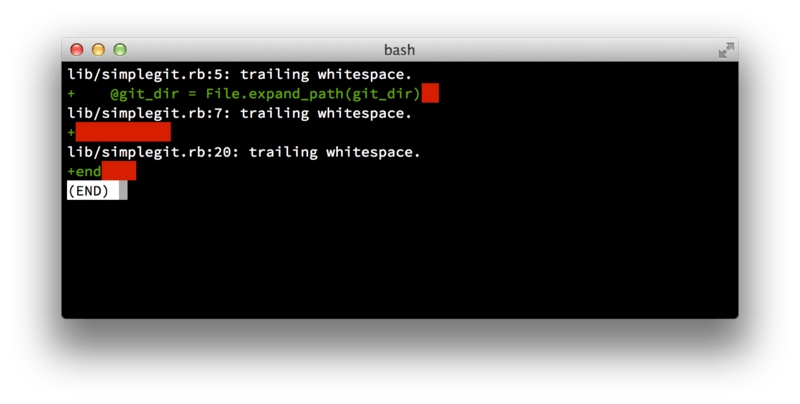
git diff --checkWenn Sie diesen Befehl vor dem Commit ausführen, können Sie feststellen, ob Sie dabei sind, Whitespace-Probleme zu committen, die andere Entwickler stören könnten.
Versuchen Sie als Nächstes, jeden Commit als logisch getrennten Satz von Änderungen zu gestalten. Wenn möglich, versuchen Sie, Ihre Änderungen verdaulich zu machen – coden Sie nicht ein ganzes Wochenende lang an fünf verschiedenen Problemen und reichen Sie sie dann am Montag alle als einen einzigen massiven Commit ein. Selbst wenn Sie am Wochenende nicht committen, verwenden Sie am Montag den Staging-Bereich, um Ihre Arbeit in mindestens einen Commit pro Problem aufzuteilen, mit einer nützlichen Nachricht pro Commit. Wenn einige der Änderungen dieselbe Datei ändern, versuchen Sie, git add --patch zu verwenden, um Dateien teilweise zu stagen (detailliert beschrieben in Interaktives Staging). Der Projekt-Snapshot am Ende des Branches ist identisch, egal ob Sie einen oder fünf Commits machen, solange alle Änderungen irgendwann hinzugefügt werden. Versuchen Sie also, es Ihren Mitentwicklern einfacher zu machen, wenn sie Ihre Änderungen überprüfen müssen.
Dieser Ansatz erleichtert auch das Herausziehen oder Zurücksetzen eines der Csets, wenn Sie es später benötigen. Das Umschreiben der Historie beschreibt eine Reihe nützlicher Git-Tricks zum Umschreiben der Historie und zum interaktiven Staging von Dateien – verwenden Sie diese Werkzeuge, um eine saubere und verständliche Historie zu erstellen, bevor Sie die Arbeit an jemand anderen senden.
Das Letzte, was Sie beachten sollten, ist die Commit-Nachricht. Die Gewohnheit, qualitativ hochwertige Commit-Nachrichten zu erstellen, erleichtert die Verwendung von Git und die Zusammenarbeit damit erheblich. Als allgemeine Regel sollten Ihre Nachrichten mit einer einzelnen Zeile beginnen, die nicht mehr als etwa 50 Zeichen lang ist und den Cset prägnant beschreibt, gefolgt von einer Leerzeile und dann einer detaillierteren Erklärung. Das Git-Projekt verlangt, dass die detailliertere Erklärung Ihre Motivation für die Änderung und den Kontrast Ihrer Implementierung mit dem vorherigen Verhalten enthält – dies ist eine gute Richtlinie. Schreiben Sie Ihre Commit-Nachricht im Imperativ: "Fehler beheben" und nicht "Behobene Fehler" oder "Behebt Fehler". Hier ist eine Vorlage, der Sie folgen können, die wir leicht von einer ursprünglich von Tim Pope verfassten angepasst haben
Capitalized, short (50 chars or less) summary
More detailed explanatory text, if necessary. Wrap it to about 72
characters or so. In some contexts, the first line is treated as the
subject of an email and the rest of the text as the body. The blank
line separating the summary from the body is critical (unless you omit
the body entirely); tools like rebase will confuse you if you run the
two together.
Write your commit message in the imperative: "Fix bug" and not "Fixed bug"
or "Fixes bug." This convention matches up with commit messages generated
by commands like git merge and git revert.
Further paragraphs come after blank lines.
- Bullet points are okay, too
- Typically a hyphen or asterisk is used for the bullet, followed by a
single space, with blank lines in between, but conventions vary here
- Use a hanging indentWenn alle Ihre Commit-Nachrichten diesem Modell folgen, wird es für Sie und die Entwickler, mit denen Sie zusammenarbeiten, viel einfacher. Das Git-Projekt hat gut formatierte Commit-Nachrichten – versuchen Sie, git log --no-merges dort auszuführen, um zu sehen, wie eine gut formatierte Projekt-Commit-Historie aussieht.
|
Hinweis
|
Tun Sie, was wir sagen, nicht was wir tun.
Aus Gründen der Kürze haben viele Beispiele in diesem Buch keine gut formatierten Commit-Nachrichten wie diese; stattdessen verwenden wir einfach die Option Kurz gesagt: Tun Sie, was wir sagen, nicht was wir tun. |
Privates kleines Team
Das einfachste Szenario, dem Sie wahrscheinlich begegnen werden, ist ein privates Projekt mit ein oder zwei anderen Entwicklern. "Privat" bedeutet in diesem Kontext Closed-Source – nicht für die Außenwelt zugänglich. Sie und die anderen Entwickler haben alle Push-Zugriff auf das Repository.
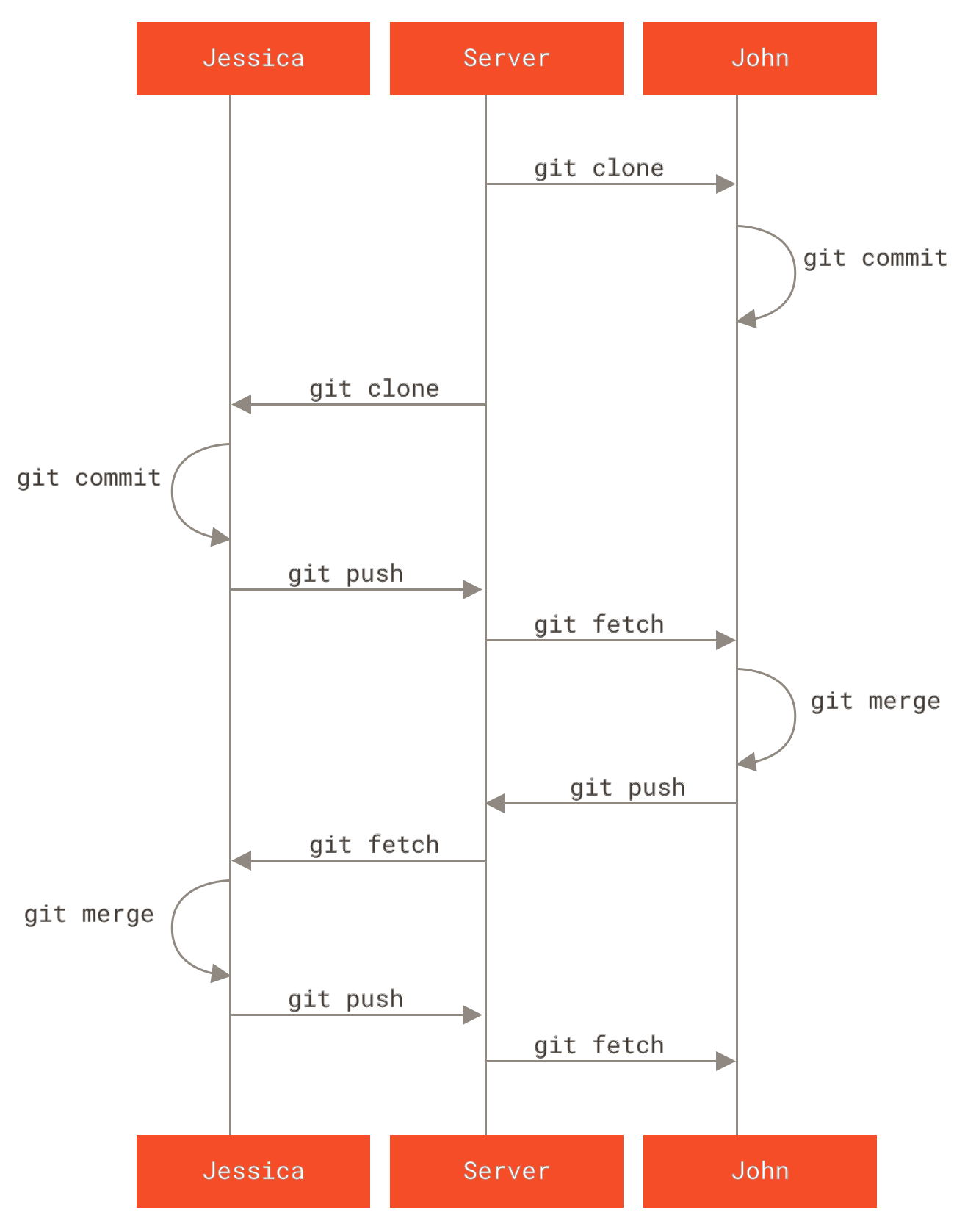
In dieser Umgebung können Sie einem Workflow folgen, der dem ähnelt, was Sie bei der Verwendung von Subversion oder einem anderen zentralisierten System tun würden. Sie profitieren immer noch von Dingen wie Offline-Committing und wesentlich einfacherem Branching und Merging, aber der Workflow kann sehr ähnlich sein; der Hauptunterschied besteht darin, dass Merges clientseitig und nicht auf dem Server zum Zeitpunkt des Commits stattfinden. Lassen Sie uns sehen, wie es aussehen könnte, wenn zwei Entwickler beginnen, mit einem gemeinsamen Repository zusammenzuarbeiten. Der erste Entwickler, John, klont das Repository, macht eine Änderung und committet lokal. Die Protokollmeldungen wurden in diesen Beispielen durch … ersetzt, um sie etwas zu verkürzen.
# John's Machine
$ git clone john@githost:simplegit.git
Cloning into 'simplegit'...
...
$ cd simplegit/
$ vim lib/simplegit.rb
$ git commit -am 'Remove invalid default value'
[master 738ee87] Remove invalid default value
1 files changed, 1 insertions(+), 1 deletions(-)Der zweite Entwickler, Jessica, tut dasselbe – klont das Repository und committet eine Änderung
# Jessica's Machine
$ git clone jessica@githost:simplegit.git
Cloning into 'simplegit'...
...
$ cd simplegit/
$ vim TODO
$ git commit -am 'Add reset task'
[master fbff5bc] Add reset task
1 files changed, 1 insertions(+), 0 deletions(-)Nun pusht Jessica ihre Arbeit auf den Server, was einwandfrei funktioniert
# Jessica's Machine
$ git push origin master
...
To jessica@githost:simplegit.git
1edee6b..fbff5bc master -> masterDie letzte Zeile der obigen Ausgabe zeigt eine nützliche Rückmeldung der Push-Operation. Das Grundformat ist <oldref>..<newref> fromref → toref, wobei oldref die alte Referenz, newref die neue Referenz, fromref der Name der lokalen Referenz, die gepusht wird, und toref der Name der entfernten Referenz, die aktualisiert wird, bedeutet. Sie werden ähnliche Ausgaben wie diese unten in den Diskussionen sehen, so dass ein grundlegendes Verständnis der Bedeutung helfen wird, die verschiedenen Zustände der Repositories zu verstehen. Weitere Details finden Sie in der Dokumentation für git-push.
Weiter mit diesem Beispiel, kurz darauf macht John einige Änderungen, committet sie in seinem lokalen Repository und versucht, sie auf denselben Server zu pushen
# John's Machine
$ git push origin master
To john@githost:simplegit.git
! [rejected] master -> master (non-fast forward)
error: failed to push some refs to 'john@githost:simplegit.git'In diesem Fall schlägt Johns Push aufgrund von Jessicas früherem Push *ihrer* Änderungen fehl. Dies ist besonders wichtig zu verstehen, wenn Sie an Subversion gewöhnt sind, da Sie feststellen werden, dass die beiden Entwickler nicht dieselbe Datei bearbeitet haben. Obwohl Subversion dies auf dem Server automatisch tut, wenn unterschiedliche Dateien bearbeitet werden, müssen Sie bei Git *zuerst* die Commits lokal zusammenführen. Mit anderen Worten, John muss zuerst Jessicas Upstream-Änderungen abrufen und sie in sein lokales Repository zusammenführen, bevor er pushen darf.
Als erster Schritt holt John Jessicas Arbeit (dies *holt* nur Jessicas Upstream-Arbeit, es führt sie noch nicht mit Johns Arbeit zusammen)
$ git fetch origin
...
From john@githost:simplegit
+ 049d078...fbff5bc master -> origin/masterZu diesem Zeitpunkt sieht Johns lokales Repository ungefähr so aus
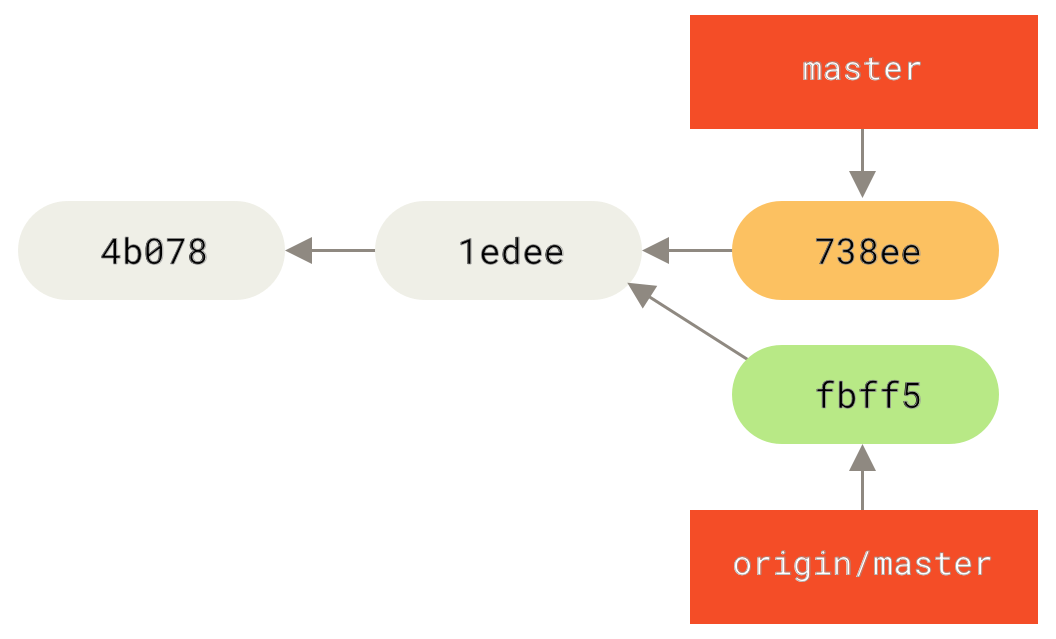
Nun kann John Jessicas Arbeit, die er geholt hat, mit seiner eigenen lokalen Arbeit zusammenführen
$ git merge origin/master
Merge made by the 'recursive' strategy.
TODO | 1 +
1 files changed, 1 insertions(+), 0 deletions(-)Solange diese lokale Zusammenführung reibungslos verläuft, wird Johns aktualisierte Historie nun so aussehen
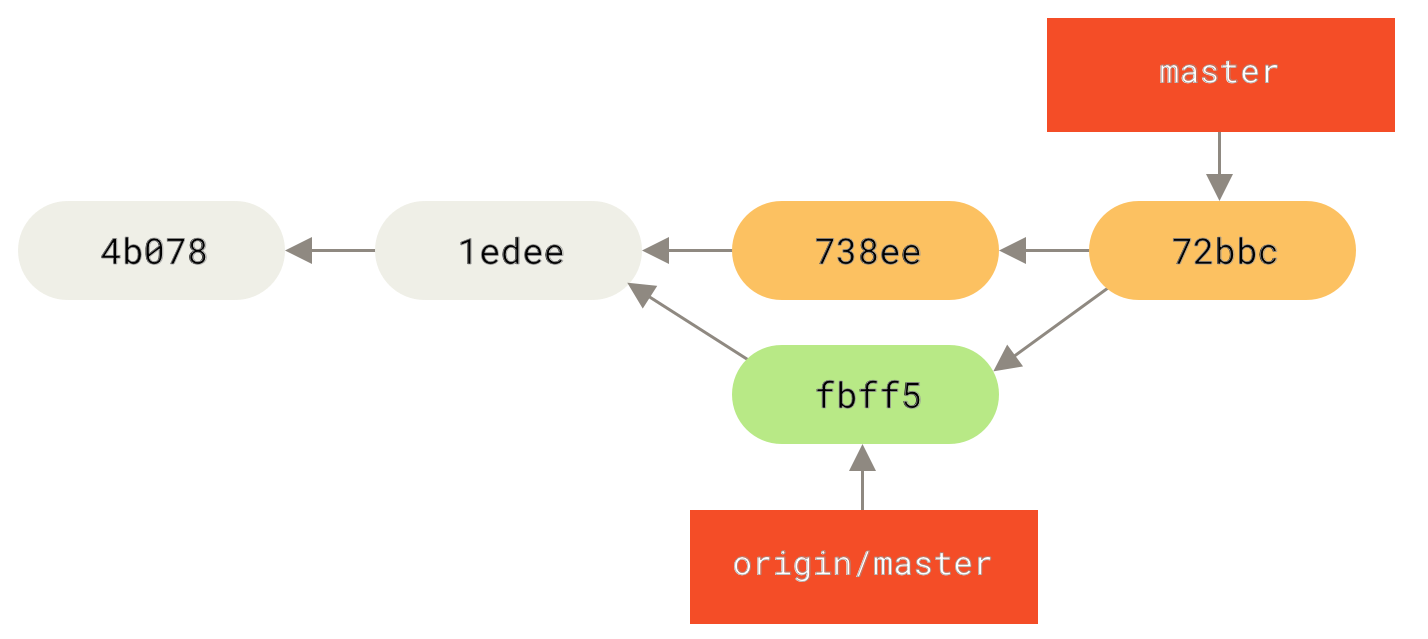
origin/masterZu diesem Zeitpunkt möchte John möglicherweise diesen neuen Code testen, um sicherzustellen, dass Jessicas Arbeit keine seiner beeinträchtigt, und solange alles in Ordnung zu sein scheint, kann er die neue zusammengeführte Arbeit endlich auf den Server pushen
$ git push origin master
...
To john@githost:simplegit.git
fbff5bc..72bbc59 master -> masterAm Ende wird Johns Commit-Historie so aussehen
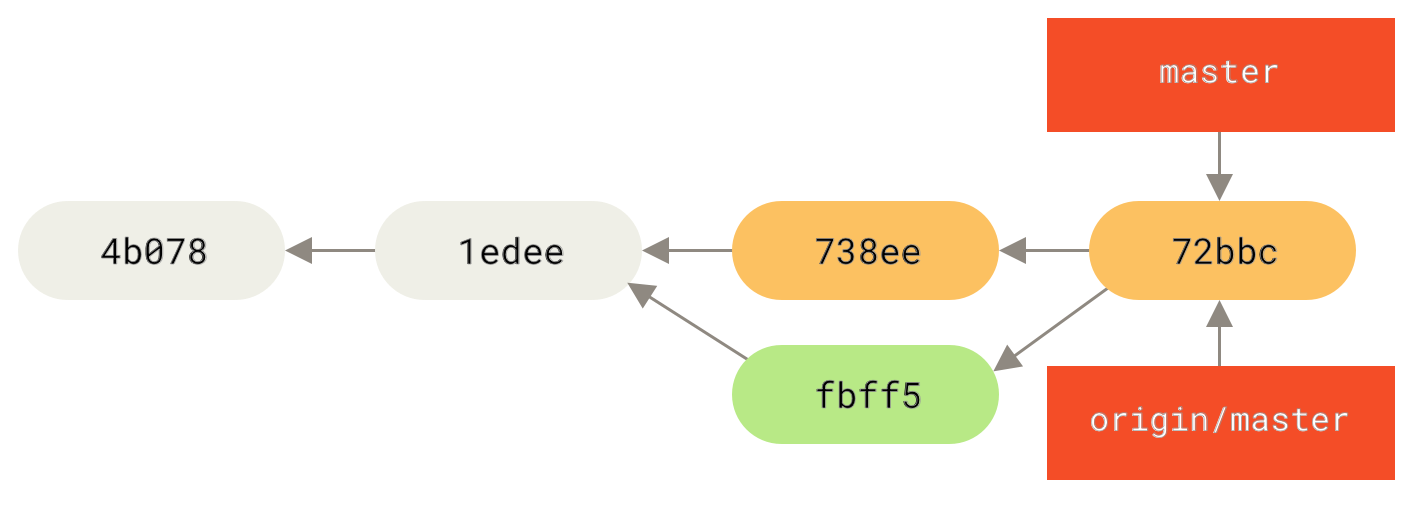
origin-ServerIn der Zwischenzeit hat Jessica einen neuen Topic-Branch namens issue54 erstellt und drei Commits an diesem Branch vorgenommen. Sie hat Johns Änderungen noch nicht geholt, daher sieht ihre Commit-Historie so aus
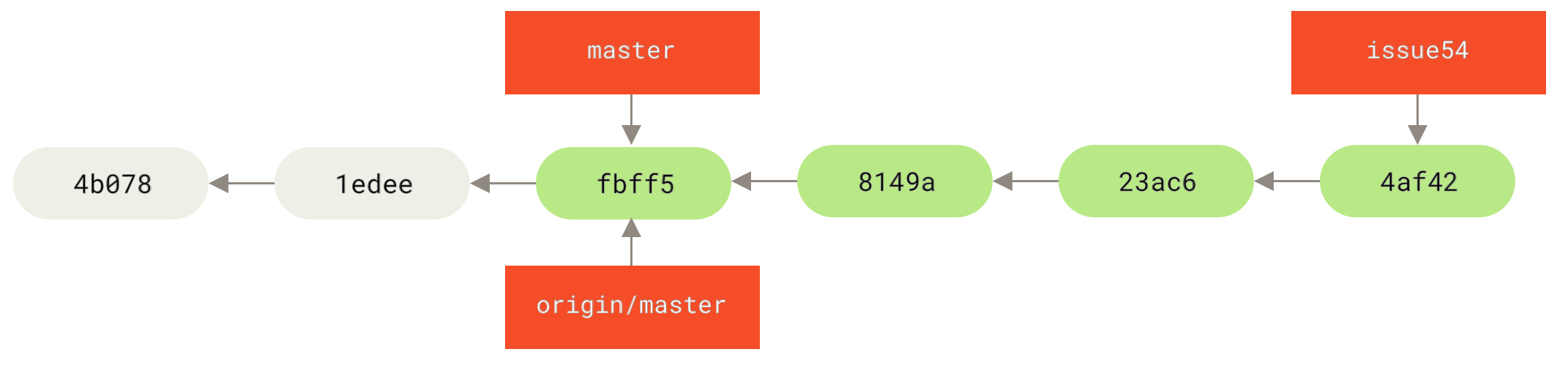
Plötzlich erfährt Jessica, dass John neue Arbeit auf den Server gepusht hat und sie sie sich ansehen möchte, also holt sie mit git fetch alle neuen Inhalte vom Server, die sie noch nicht hat
# Jessica's Machine
$ git fetch origin
...
From jessica@githost:simplegit
fbff5bc..72bbc59 master -> origin/masterDas zieht die Arbeit herunter, die John in der Zwischenzeit hochgeladen hat. Jessicas Historie sieht nun so aus
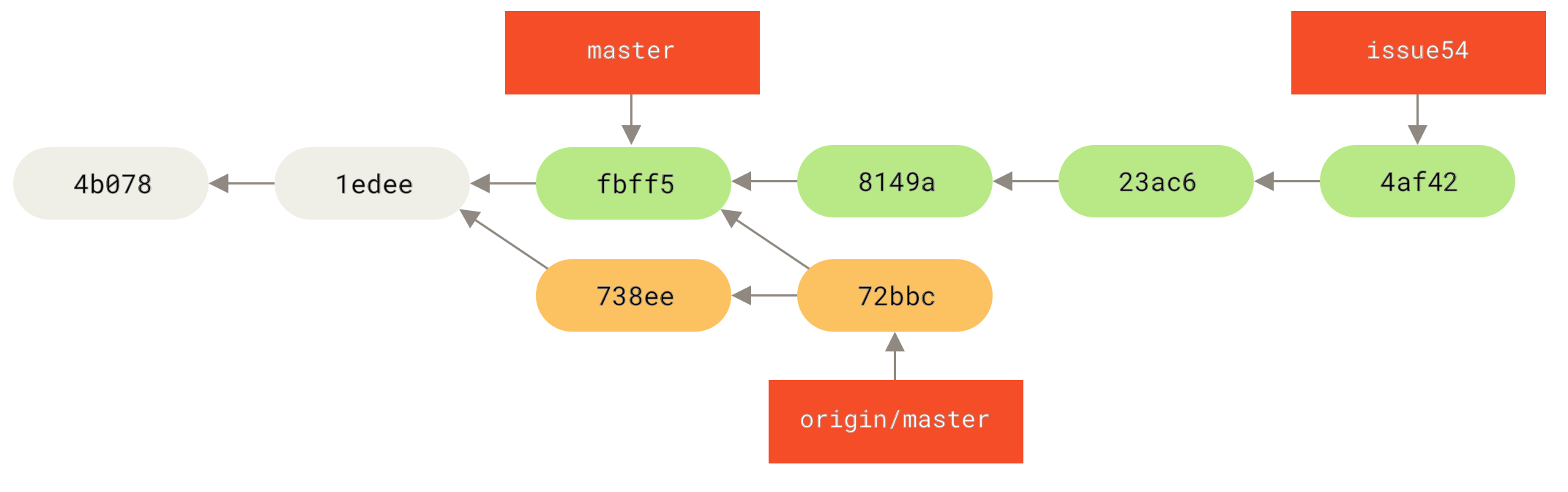
Jessica denkt, ihr Topic-Branch sei bereit, aber sie möchte wissen, welcher Teil von Johns geholter Arbeit sie zusammenführen muss, damit sie pushen kann. Sie führt git log aus, um das herauszufinden
$ git log --no-merges issue54..origin/master
commit 738ee872852dfaa9d6634e0dea7a324040193016
Author: John Smith <jsmith@example.com>
Date: Fri May 29 16:01:27 2009 -0700
Remove invalid default valueDie Syntax issue54..origin/master ist ein Log-Filter, der Git auffordert, nur die Commits anzuzeigen, die auf dem letzteren Branch (in diesem Fall origin/master) liegen und die nicht auf dem ersten Branch (in diesem Fall issue54) liegen. Wir werden diese Syntax im Detail in Commit-Bereiche behandeln.
Aus der obigen Ausgabe können wir sehen, dass es einen einzigen Commit gibt, den John gemacht hat und den Jessica noch nicht in ihre lokale Arbeit integriert hat. Wenn sie origin/master zusammenführt, wird dieser einzelne Commit ihre lokale Arbeit ändern.
Nun kann Jessica ihre Topic-Arbeit in ihren master-Branch einfügen, Johns Arbeit (origin/master) in ihren master-Branch einfügen und dann wieder auf den Server pushen.
Zuerst (nachdem sie alle Arbeiten an ihrem issue54-Topic-Branch committet hat) wechselt Jessica zurück zu ihrem master-Branch, um all diese Arbeiten zu integrieren
$ git checkout master
Switched to branch 'master'
Your branch is behind 'origin/master' by 2 commits, and can be fast-forwarded.Jessica kann entweder origin/master oder issue54 zuerst zusammenführen – sie sind beide Upstream, daher spielt die Reihenfolge keine Rolle. Der End-Snapshot sollte unabhängig von der gewählten Reihenfolge identisch sein; nur die Historie wird unterschiedlich sein. Sie entscheidet sich, zuerst den issue54-Branch zusammenzuführen
$ git merge issue54
Updating fbff5bc..4af4298
Fast forward
README | 1 +
lib/simplegit.rb | 6 +++++-
2 files changed, 6 insertions(+), 1 deletions(-)Es treten keine Probleme auf; wie Sie sehen können, war es ein einfacher Fast-Forward-Merge. Jessica schließt nun den lokalen Zusammenführungsprozess ab, indem sie Johns zuvor geholte Arbeit zusammenführt, die sich im origin/master-Branch befindet
$ git merge origin/master
Auto-merging lib/simplegit.rb
Merge made by the 'recursive' strategy.
lib/simplegit.rb | 2 +-
1 files changed, 1 insertions(+), 1 deletions(-)Alles wird sauber zusammengeführt, und Jessicas Historie sieht nun so aus
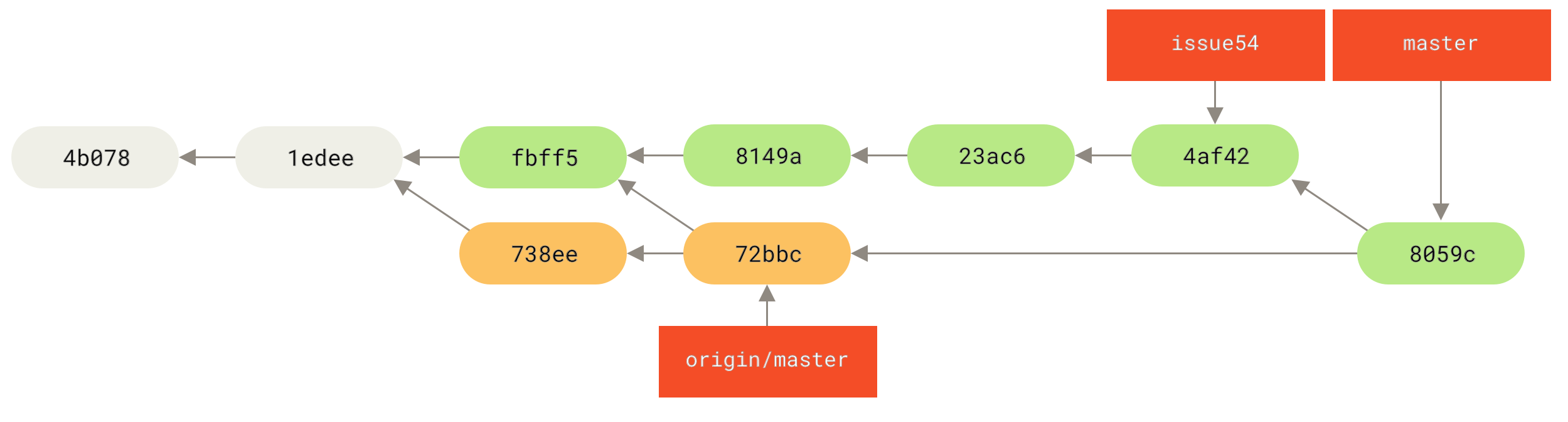
Nun ist origin/master von Jessicas master-Branch erreichbar, so dass sie erfolgreich pushen können sollte (vorausgesetzt, John hat inzwischen keine weiteren Änderungen gepusht)
$ git push origin master
...
To jessica@githost:simplegit.git
72bbc59..8059c15 master -> masterJeder Entwickler hat ein paar Mal committet und die Arbeit des anderen erfolgreich zusammengeführt.
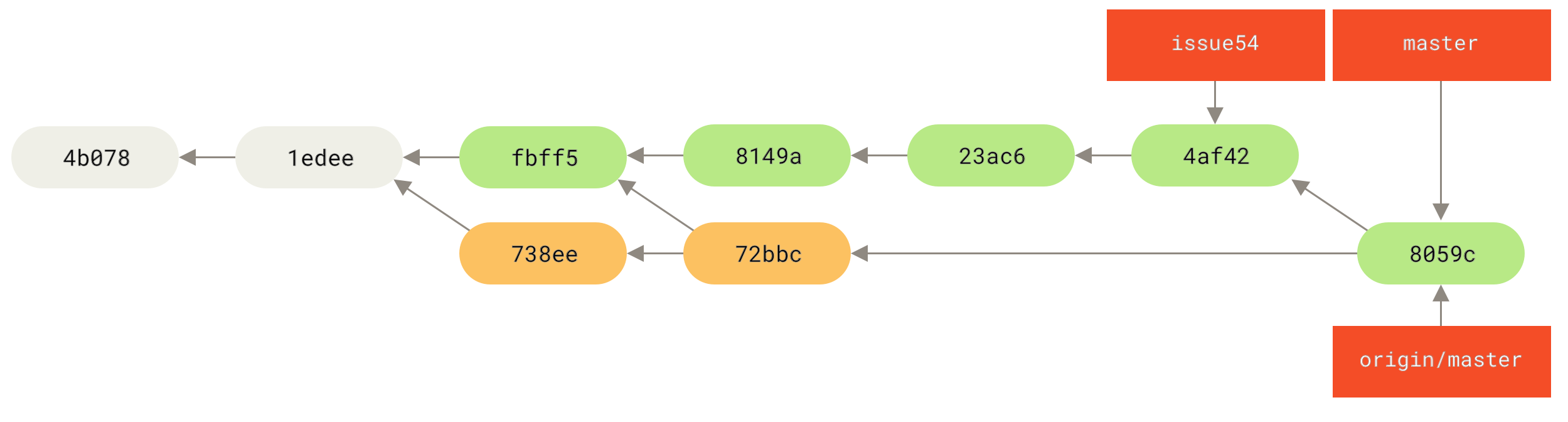
Das ist einer der einfachsten Workflows. Sie arbeiten eine Weile (im Allgemeinen in einem Topic-Branch) und fügen diese Arbeit in Ihren master-Branch ein, wenn sie zur Integration bereit ist. Wenn Sie diese Arbeit teilen möchten, holen und führen Sie Ihren master von origin/master zusammen, falls er sich geändert hat, und pushen Sie ihn schließlich in den master-Branch auf dem Server. Die allgemeine Reihenfolge ist ungefähr so
Privates verwaltetes Team
Im nächsten Szenario werden wir uns die Rollen von Mitwirkenden in einer größeren privaten Gruppe ansehen. Sie lernen, wie man in einer Umgebung arbeitet, in der kleine Gruppen an Features zusammenarbeiten, und diese teambasierten Beiträge dann von einer anderen Partei integriert werden.
Nehmen wir an, John und Jessica arbeiten gemeinsam an einem Feature (nennen wir es "featureA"), während Jessica und ein dritter Entwickler, Josie, an einem zweiten (nennen wir es "featureB") arbeiten. In diesem Fall verwendet das Unternehmen eine Art Integrationsmanager-Workflow, bei dem die Arbeit der einzelnen Gruppen nur von bestimmten Ingenieuren integriert wird und der master-Branch des Haupt-Repos nur von diesen Ingenieuren aktualisiert werden kann. In diesem Szenario wird die gesamte Arbeit in teambasierten Branches durchgeführt und später von den Integratoren zusammengeführt.
Folgen wir Jessicas Workflow, während sie an ihren beiden Features arbeitet und parallel mit zwei verschiedenen Entwicklern in dieser Umgebung zusammenarbeitet. Da sie ihr Repository bereits geklont hat, beschließt sie, zuerst an featureA zu arbeiten. Sie erstellt einen neuen Branch für das Feature und leistet dort einige Arbeiten
# Jessica's Machine
$ git checkout -b featureA
Switched to a new branch 'featureA'
$ vim lib/simplegit.rb
$ git commit -am 'Add limit to log function'
[featureA 3300904] Add limit to log function
1 files changed, 1 insertions(+), 1 deletions(-)Zu diesem Zeitpunkt muss sie ihre Arbeit mit John teilen, also pusht sie ihre featureA-Branch-Commits auf den Server. Jessica hat keinen Push-Zugriff auf den master-Branch – nur die Integratoren haben ihn – also muss sie auf einen anderen Branch pushen, um mit John zusammenzuarbeiten
$ git push -u origin featureA
...
To jessica@githost:simplegit.git
* [new branch] featureA -> featureAJessica E-Mailt John, um ihm mitzuteilen, dass sie einige Arbeiten in einen Branch namens featureA gepusht hat und er sie sich jetzt ansehen kann. Während sie auf Feedback von John wartet, beschließt Jessica, mit Josie an featureB zu arbeiten. Dazu startet sie einen neuen Feature-Branch, der auf dem master-Branch des Servers basiert
# Jessica's Machine
$ git fetch origin
$ git checkout -b featureB origin/master
Switched to a new branch 'featureB'Nun macht Jessica ein paar Commits auf dem featureB-Branch
$ vim lib/simplegit.rb
$ git commit -am 'Make ls-tree function recursive'
[featureB e5b0fdc] Make ls-tree function recursive
1 files changed, 1 insertions(+), 1 deletions(-)
$ vim lib/simplegit.rb
$ git commit -am 'Add ls-files'
[featureB 8512791] Add ls-files
1 files changed, 5 insertions(+), 0 deletions(-)Jessicas Repository sieht nun so aus
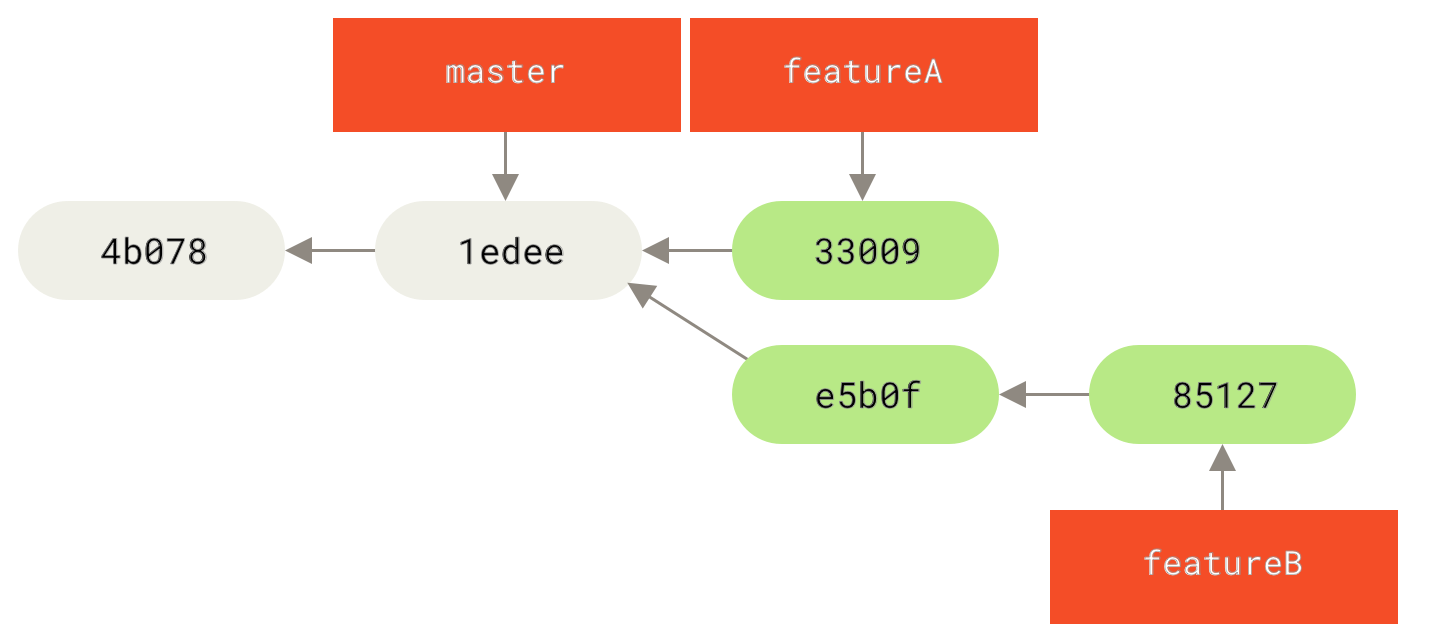
Sie ist bereit, ihre Arbeit zu pushen, erhält aber eine E-Mail von Josie, dass ein Branch mit einigen anfänglichen "featureB"-Arbeiten bereits als Branch featureBee auf den Server gepusht wurde. Jessica muss diese Änderungen mit ihren eigenen zusammenführen, bevor sie ihre Arbeit auf den Server pushen kann. Jessica holt zuerst Josies Änderungen mit git fetch
$ git fetch origin
...
From jessica@githost:simplegit
* [new branch] featureBee -> origin/featureBeeUnter der Annahme, dass Jessica sich immer noch auf ihrem ausgecheckten featureB-Branch befindet, kann sie nun Josies Arbeit mit git merge in diesen Branch einfügen
$ git merge origin/featureBee
Auto-merging lib/simplegit.rb
Merge made by the 'recursive' strategy.
lib/simplegit.rb | 4 ++++
1 files changed, 4 insertions(+), 0 deletions(-)Zu diesem Zeitpunkt möchte Jessica all diese zusammengeführte "featureB"-Arbeit zurück auf den Server pushen, aber sie möchte nicht einfach ihren eigenen featureB-Branch pushen. Vielmehr möchte Jessica, da Josie bereits einen Upstream-featureBee-Branch begonnen hat, zu *diesem* Branch pushen, was sie mit
$ git push -u origin featureB:featureBee
...
To jessica@githost:simplegit.git
fba9af8..cd685d1 featureB -> featureBeeDies wird als Refspec bezeichnet. Sehen Sie sich Die Refspec für eine detailliertere Diskussion von Git-Refspecs und verschiedenen Dingen, die Sie damit tun können, an. Beachten Sie auch das Flag -u; dies steht für --set-upstream, das die Branches für einfacheres Pushen und Ziehen zu einem späteren Zeitpunkt konfiguriert.
Plötzlich erhält Jessica eine E-Mail von John, der ihr mitteilt, dass er einige Änderungen an dem featureA-Branch, an dem sie zusammenarbeiten, gepusht hat, und bittet Jessica, sich diese anzusehen. Wiederum führt Jessica ein einfaches git fetch aus, um *alle* neuen Inhalte vom Server zu holen, einschließlich (natürlich) Johns neuestem Werk
$ git fetch origin
...
From jessica@githost:simplegit
3300904..aad881d featureA -> origin/featureAJessica kann das Log von Johns neuer Arbeit anzeigen, indem sie den Inhalt des neu geholten featureA-Branches mit ihrer lokalen Kopie desselben Branches vergleicht
$ git log featureA..origin/featureA
commit aad881d154acdaeb2b6b18ea0e827ed8a6d671e6
Author: John Smith <jsmith@example.com>
Date: Fri May 29 19:57:33 2009 -0700
Increase log output to 30 from 25Wenn Jessica gefällt, was sie sieht, kann sie Johns neue Arbeit mit
$ git checkout featureA
Switched to branch 'featureA'
$ git merge origin/featureA
Updating 3300904..aad881d
Fast forward
lib/simplegit.rb | 10 +++++++++-
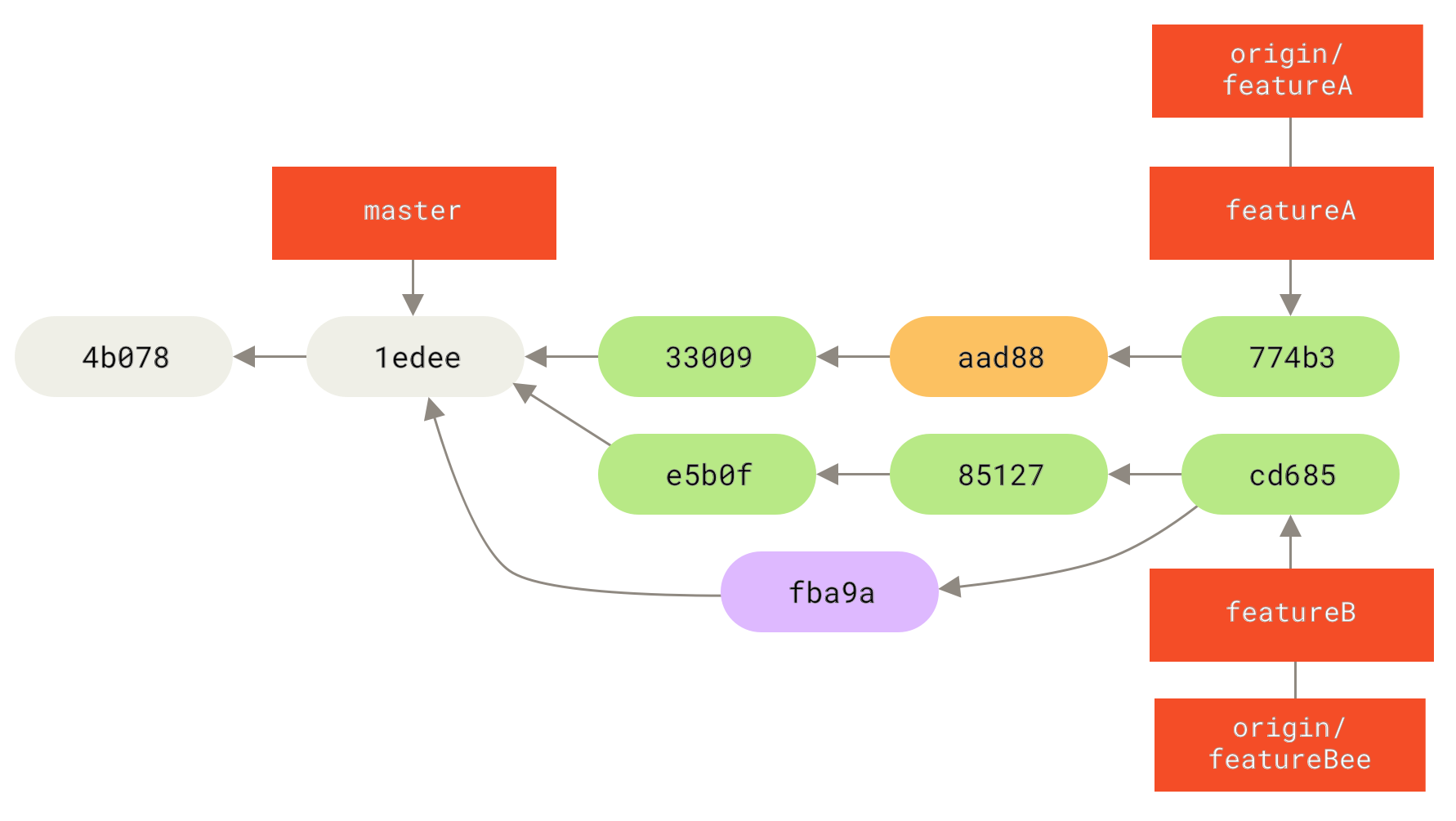
1 files changed, 9 insertions(+), 1 deletions(-)Schließlich möchte Jessica vielleicht ein paar kleine Änderungen an all diesen zusammengeführten Inhalten vornehmen, also kann sie diese Änderungen vornehmen, sie in ihren lokalen featureA-Branch committen und das Endergebnis zurück auf den Server pushen
$ git commit -am 'Add small tweak to merged content'
[featureA 774b3ed] Add small tweak to merged content
1 files changed, 1 insertions(+), 1 deletions(-)
$ git push
...
To jessica@githost:simplegit.git
3300904..774b3ed featureA -> featureAJessicas Commit-Historie sieht nun ungefähr so aus
Irgendwann informieren Jessica, Josie und John die Integratoren, dass die featureA- und featureBee-Branches auf dem Server für die Integration in die Hauptlinie bereit sind. Nachdem die Integratoren diese Branches in die Hauptlinie zusammengeführt haben, holt ein Fetch den neuen Merge-Commit und lässt die Historie so aussehen
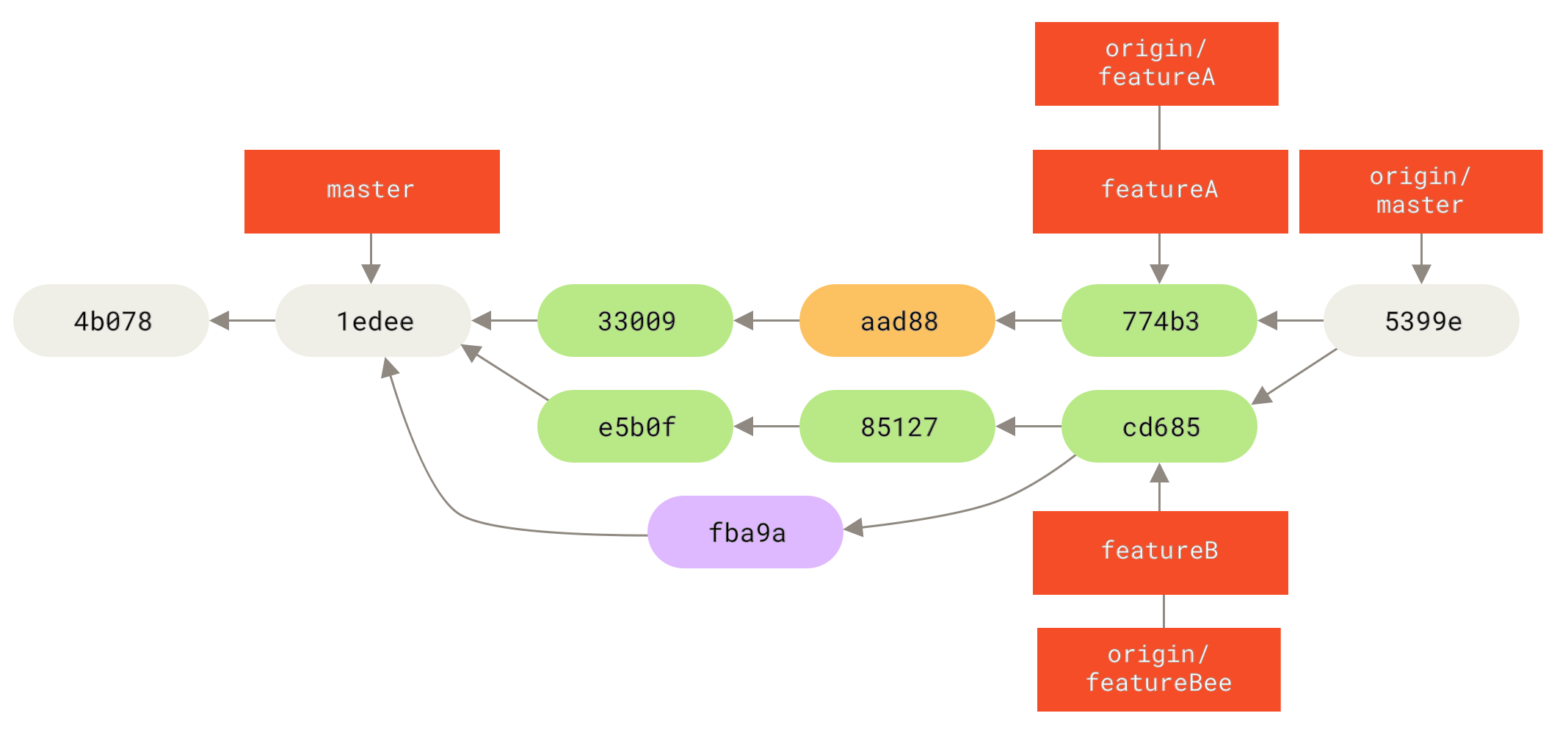
Viele Gruppen wechseln zu Git wegen dieser Fähigkeit, mehrere Teams parallel arbeiten zu lassen und die verschiedenen Arbeitsstränge spät im Prozess zusammenzuführen. Die Fähigkeit kleinerer Untergruppen eines Teams, über entfernte Branches zusammenzuarbeiten, ohne notwendigerweise das gesamte Team einbeziehen oder behindern zu müssen, ist ein großer Vorteil von Git. Die Reihenfolge für den hier gezeigten Workflow ist ungefähr so
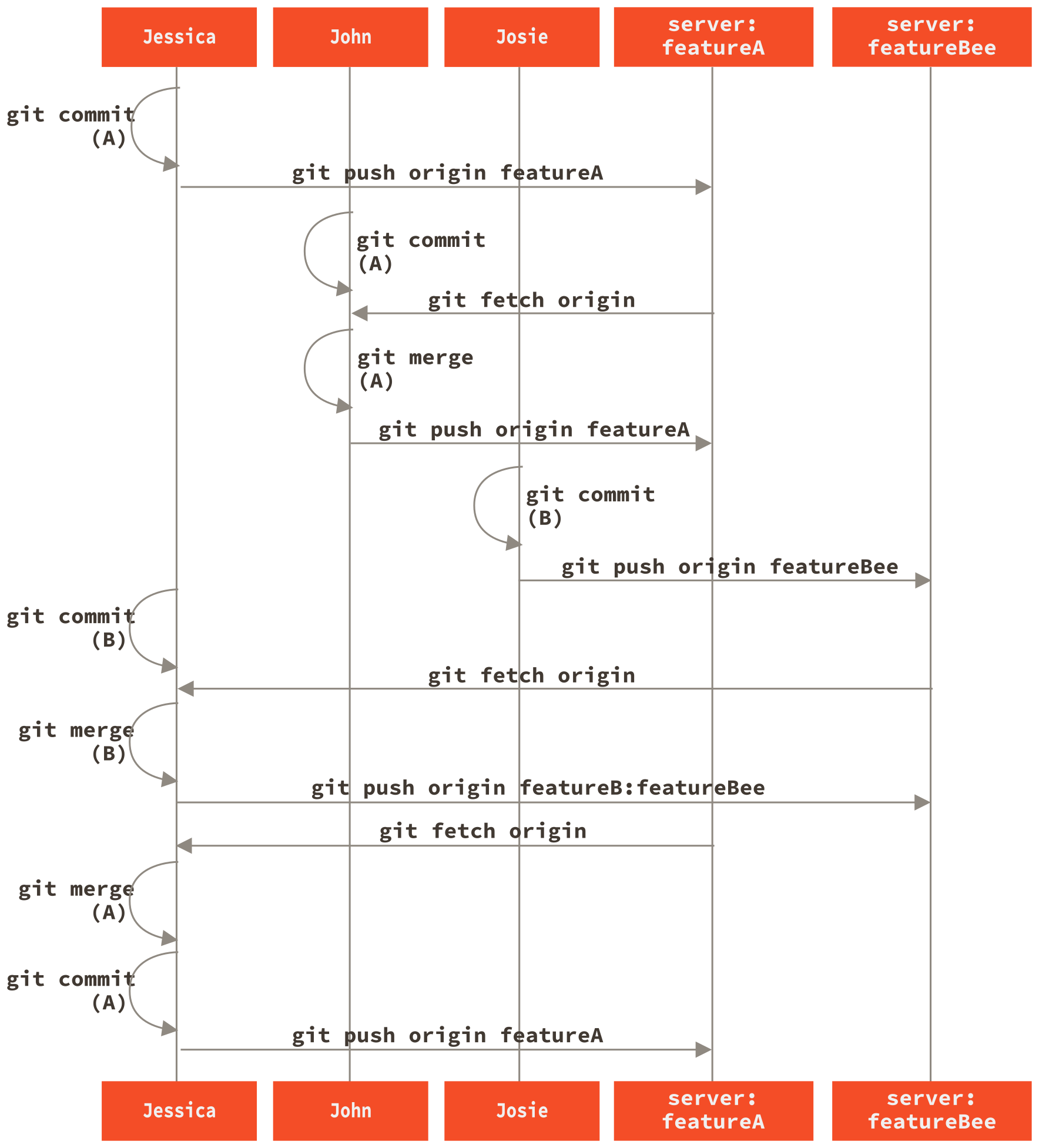
Gegabeltes öffentliches Projekt
Das Mitwirken an öffentlichen Projekten ist etwas anders. Da Sie nicht die Berechtigung haben, Branches im Projekt direkt zu aktualisieren, müssen Sie die Arbeit auf andere Weise an die Maintainer bringen. Dieses erste Beispiel beschreibt das Mitwirken über Forking auf Git-Hosts, die einfaches Forking unterstützen. Viele Hosting-Sites unterstützen dies (einschließlich GitHub, BitBucket, repo.or.cz und andere), und viele Projekt-Maintainer erwarten diesen Stil des Mitwirkens. Der nächste Abschnitt befasst sich mit Projekten, die beigesteuerte Patches per E-Mail akzeptieren.
Zuerst möchten Sie wahrscheinlich das Hauptrepository klonen, einen Topic-Branch für den Patch oder die Patch-Serie erstellen, die Sie beitragen möchten, und dort Ihre Arbeit leisten. Die Reihenfolge sieht im Grunde so aus
$ git clone <url>
$ cd project
$ git checkout -b featureA
... work ...
$ git commit
... work ...
$ git commit|
Hinweis
|
Möglicherweise möchten Sie |
Wenn Ihre Branch-Arbeit abgeschlossen ist und Sie bereit sind, sie an die Maintainer zurückzugeben, gehen Sie zur ursprünglichen Projektseite und klicken Sie auf die Schaltfläche "Fork", um Ihren eigenen beschreibbaren Fork des Projekts zu erstellen. Sie müssen dann diese Repository-URL als neues Remote zu Ihrem lokalen Repository hinzufügen; in diesem Beispiel nennen wir es myfork
$ git remote add myfork <url>Sie müssen dann Ihre neue Arbeit in dieses Repository pushen. Es ist am einfachsten, den Topic-Branch, an dem Sie arbeiten, in Ihr gegabeltes Repository zu pushen, anstatt diese Arbeit in Ihren master-Branch zu integrieren und diesen zu pushen. Der Grund dafür ist, dass Sie, wenn Ihre Arbeit nicht akzeptiert wird oder "cherry-picked" wird, Ihren master-Branch nicht zurückspulen müssen (die Git cherry-pick Operation wird detaillierter in Rebase- und Cherry-Pick-Workflows behandelt). Wenn die Maintainer Ihre Arbeit mergen, rebasen oder cherry-picken, erhalten Sie sie irgendwann über das Ziehen von ihrem Repository zurück.
In jedem Fall können Sie Ihre Arbeit mit
$ git push -u myfork featureASobald Ihre Arbeit in Ihre Fork des Repositories gepusht wurde, müssen Sie die Maintainer des ursprünglichen Projekts benachrichtigen, dass Sie Arbeit haben, die sie zusammenführen möchten. Dies wird oft als Pull Request bezeichnet, und Sie generieren normalerweise einen solchen Request entweder über die Website – GitHub hat seinen eigenen "Pull Request"-Mechanismus, den wir in GitHub behandeln werden – oder Sie können den Befehl git request-pull ausführen und die anschließende Ausgabe manuell an den Projekt-Maintainer senden.
Der Befehl git request-pull nimmt den Basis-Branch, in den Sie Ihren Topic-Branch ziehen möchten, und die Git-Repository-URL, von der Sie möchten, dass sie ziehen, und erzeugt eine Zusammenfassung aller Änderungen, die Sie zusammengeführt haben möchten. Wenn Jessica John zum Beispiel einen Pull Request senden möchte und sie zwei Commits auf dem Topic-Branch gemacht hat, den sie gerade gepusht hat, kann sie dies tun
$ git request-pull origin/master myfork
The following changes since commit 1edee6b1d61823a2de3b09c160d7080b8d1b3a40:
Jessica Smith (1):
Create new function
are available in the git repository at:
https://githost/simplegit.git featureA
Jessica Smith (2):
Add limit to log function
Increase log output to 30 from 25
lib/simplegit.rb | 10 +++++++++-
1 files changed, 9 insertions(+), 1 deletions(-)Diese Ausgabe kann an den Maintainer gesendet werden – sie teilt ihm mit, von wo aus die Arbeit verzweigt wurde, fasst die Commits zusammen und identifiziert, von wo die neue Arbeit gezogen werden soll.
Bei einem Projekt, für das Sie nicht der Maintainer sind, ist es generell einfacher, einen Branch wie master immer origin/master verfolgen zu lassen und Ihre Arbeit in Topic-Branches zu erledigen, die Sie leicht verwerfen können, wenn sie abgelehnt werden. Das Isolieren von Arbeitsthemen in Topic-Branches erleichtert Ihnen auch das Rebasen Ihrer Arbeit, wenn die Spitze des Haupt-Repositories sich in der Zwischenzeit bewegt hat und Ihre Commits nicht mehr sauber angewendet werden. Wenn Sie beispielsweise ein zweites Thema an das Projekt senden möchten, arbeiten Sie nicht auf dem Topic-Branch weiter, den Sie gerade hochgeladen haben – beginnen Sie erneut vom master-Branch des Haupt-Repositories
$ git checkout -b featureB origin/master
... work ...
$ git commit
$ git push myfork featureB
$ git request-pull origin/master myfork
... email generated request pull to maintainer ...
$ git fetch originNun ist jedes Ihrer Themen in einem Silo enthalten – ähnlich einer Patch-Warteschlange –, das Sie umschreiben, rebasen und ändern können, ohne dass sich die Themen gegenseitig stören oder voneinander abhängen, so
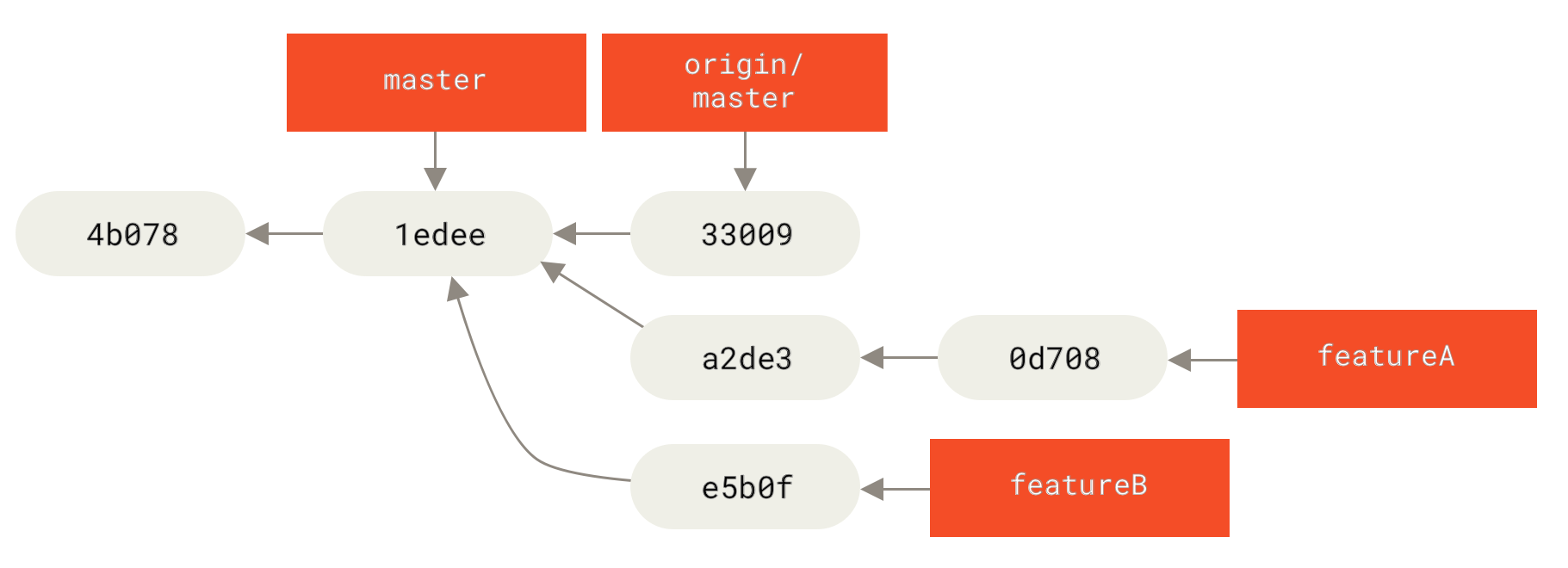
featureB-ArbeitNehmen wir an, der Projekt-Maintainer hat eine Reihe anderer Patches übernommen und Ihren ersten Branch ausprobiert, aber er lässt sich nicht mehr sauber zusammenführen. In diesem Fall können Sie versuchen, diesen Branch auf origin/master zu rebasen, die Konflikte für den Maintainer zu lösen und dann Ihre Änderungen erneut einzureichen
$ git checkout featureA
$ git rebase origin/master
$ git push -f myfork featureADies schreibt Ihre Historie um, sodass sie nun wie in Commit-Historie nach featureA-Arbeit aussieht.
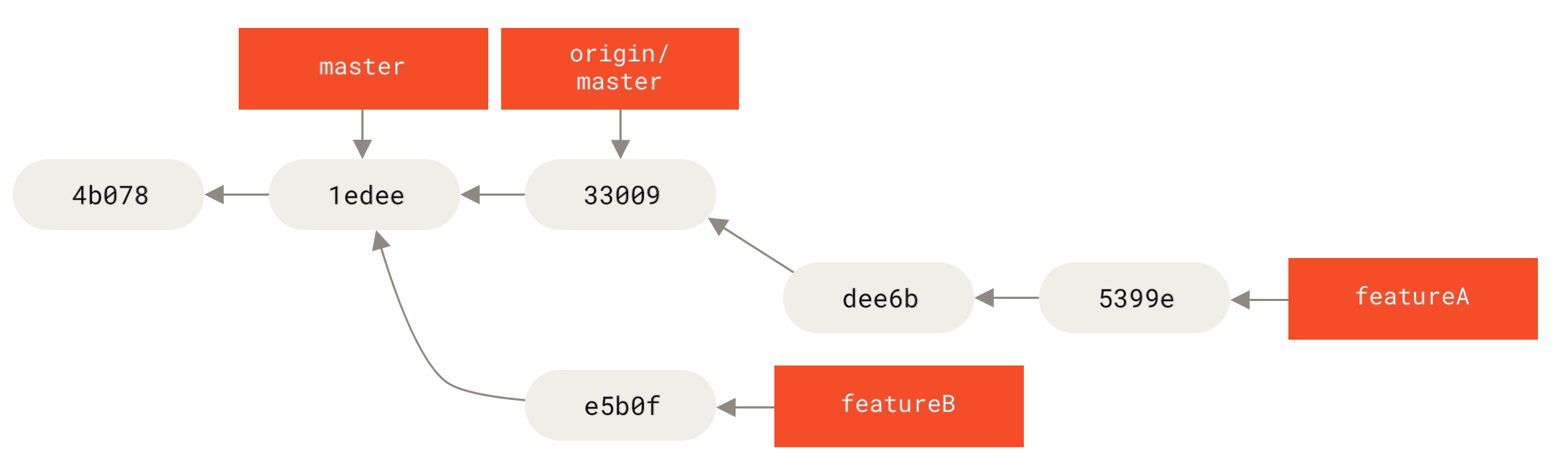
featureA-ArbeitDa Sie den Branch neu gebasst haben, müssen Sie für Ihren Push-Befehl die Option -f angeben, um den featureA-Branch auf dem Server durch einen Commit zu ersetzen, der kein Nachkomme davon ist. Eine Alternative wäre, diese neue Arbeit auf einen anderen Branch auf dem Server zu pushen (vielleicht featureAv2 genannt).
Sehen wir uns ein weiteres mögliches Szenario an: Der Maintainer hat die Arbeit in Ihrem zweiten Branch angesehen und mag das Konzept, möchte aber, dass Sie ein Implementierungsdetail ändern. Sie werden diese Gelegenheit auch nutzen, um die Arbeit basierend auf dem aktuellen master-Branch des Projekts zu verschieben. Sie starten einen neuen Branch, der auf dem aktuellen origin/master-Branch basiert, squashen die featureB-Änderungen dort, lösen alle Konflikte, nehmen die Implementierungsänderung vor und pushen diese dann als neuen Branch
$ git checkout -b featureBv2 origin/master
$ git merge --squash featureB
... change implementation ...
$ git commit
$ git push myfork featureBv2Die Option --squash nimmt die gesamte Arbeit des zusammengeführten Branches und zerlegt sie in einen einzigen Cset, der den Repository-Zustand so erzeugt, als ob eine echte Zusammenführung stattgefunden hätte, ohne tatsächlich einen Merge-Commit zu erstellen. Das bedeutet, dass Ihr zukünftiger Commit nur einen Elternteil haben wird und es Ihnen ermöglicht, alle Änderungen von einem anderen Branch einzuführen und dann weitere Änderungen vorzunehmen, bevor Sie den neuen Commit aufzeichnen. Auch die Option --no-commit kann nützlich sein, um den Merge-Commit im Falle eines Standard-Merge-Prozesses zu verzögern.
Zu diesem Zeitpunkt können Sie den Maintainer benachrichtigen, dass Sie die angeforderten Änderungen vorgenommen haben und dass er diese Änderungen in Ihrem featureBv2-Branch finden kann.
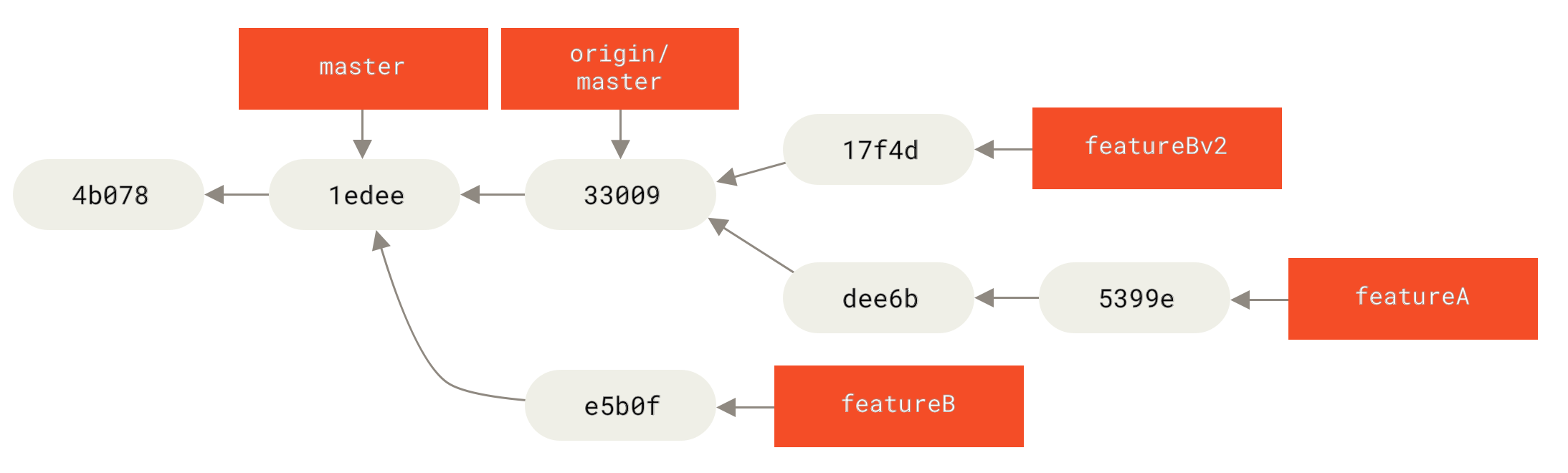
featureBv2-ArbeitÖffentliches Projekt per E-Mail
Viele Projekte haben etablierte Verfahren zur Annahme von Patches – Sie müssen die spezifischen Regeln für jedes Projekt überprüfen, da sie unterschiedlich sein werden. Da es mehrere ältere, größere Projekte gibt, die Patches über eine Entwickler-Mailingliste akzeptieren, werden wir nun ein Beispiel dafür durchgehen.
Der Workflow ist dem vorherigen Anwendungsfall ähnlich – Sie erstellen Topic-Branches für jede Patch-Serie, an der Sie arbeiten. Der Unterschied besteht darin, wie Sie sie dem Projekt übermitteln. Anstatt das Projekt zu forken und in Ihre eigene beschreibbare Version zu pushen, erstellen Sie E-Mail-Versionen jeder Commit-Serie und senden sie per E-Mail an die Entwickler-Mailingliste
$ git checkout -b topicA
... work ...
$ git commit
... work ...
$ git commitNun haben Sie zwei Commits, die Sie an die Mailingliste senden möchten. Sie verwenden git format-patch, um die im mbox-Format vorliegenden Dateien zu generieren, die Sie an die Liste senden können – es wandelt jeden Commit in eine E-Mail-Nachricht um, wobei die erste Zeile der Commit-Nachricht der Betreff und der Rest der Nachricht plus der Patch, den der Commit einführt, der Körper ist. Das Schöne daran ist, dass das Anwenden eines Patches aus einer mit format-patch generierten E-Mail alle Commit-Informationen ordnungsgemäß beibehält.
$ git format-patch -M origin/master
0001-add-limit-to-log-function.patch
0002-increase-log-output-to-30-from-25.patchDer Befehl format-patch gibt die Namen der von ihm erstellten Patch-Dateien aus. Der Schalter -M weist Git an, nach Umbenennungen zu suchen. Die Dateien sehen dann so aus
$ cat 0001-add-limit-to-log-function.patch
From 330090432754092d704da8e76ca5c05c198e71a8 Mon Sep 17 00:00:00 2001
From: Jessica Smith <jessica@example.com>
Date: Sun, 6 Apr 2008 10:17:23 -0700
Subject: [PATCH 1/2] Add limit to log function
Limit log functionality to the first 20
---
lib/simplegit.rb | 2 +-
1 files changed, 1 insertions(+), 1 deletions(-)
diff --git a/lib/simplegit.rb b/lib/simplegit.rb
index 76f47bc..f9815f1 100644
--- a/lib/simplegit.rb
+++ b/lib/simplegit.rb
@@ -14,7 +14,7 @@ class SimpleGit
end
def log(treeish = 'master')
- command("git log #{treeish}")
+ command("git log -n 20 #{treeish}")
end
def ls_tree(treeish = 'master')
--
2.1.0Sie können diese Patch-Dateien auch bearbeiten, um zusätzliche Informationen für die E-Mail-Liste hinzuzufügen, die nicht in der Commit-Nachricht erscheinen sollen. Wenn Sie Text zwischen der ----Zeile und dem Beginn des Patches (der Zeile diff --git) einfügen, können die Entwickler ihn lesen, aber dieser Inhalt wird vom Patch-Prozess ignoriert.
Um dies an eine Mailingliste zu senden, können Sie entweder die Datei in Ihr E-Mail-Programm einfügen oder sie über ein Befehlszeilenprogramm senden. Das Einfügen von Text verursacht oft Formatierungsprobleme, insbesondere bei "intelligenteren" Clients, die Zeilenumbrüche und andere Leerzeichen nicht korrekt beibehalten. Glücklicherweise bietet Git ein Werkzeug, das Ihnen hilft, ordnungsgemäß formatierte Patches über IMAP zu senden, was für Sie einfacher sein kann. Wir werden demonstrieren, wie man einen Patch über Gmail sendet, was zufällig der E-Mail-Agent ist, den wir am besten kennen; detaillierte Anweisungen für eine Reihe von Mail-Programmen finden Sie am Ende der bereits erwähnten Datei Documentation/SubmittingPatches im Git-Quellcode.
Zuerst müssen Sie den IMAP-Abschnitt in Ihrer Datei ~/.gitconfig einrichten. Sie können jeden Wert separat mit einer Reihe von git config-Befehlen festlegen oder sie manuell hinzufügen, aber am Ende sollte Ihre Konfigurationsdatei ungefähr so aussehen
[imap]
folder = "[Gmail]/Drafts"
host = imaps://imap.gmail.com
user = user@gmail.com
pass = YX]8g76G_2^sFbd
port = 993
sslverify = falseWenn Ihr IMAP-Server kein SSL verwendet, sind die letzten beiden Zeilen wahrscheinlich nicht notwendig und der Hostwert ist imap:// anstelle von imaps://. Wenn dies eingerichtet ist, können Sie git imap-send verwenden, um die Patch-Serie im Ordner "Entwürfe" des angegebenen IMAP-Servers zu platzieren
$ cat *.patch |git imap-send
Resolving imap.gmail.com... ok
Connecting to [74.125.142.109]:993... ok
Logging in...
sending 2 messages
100% (2/2) doneZu diesem Zeitpunkt sollten Sie in der Lage sein, zu Ihrem Entwurfsordner zu gehen, das Feld "An" in die Mailingliste zu ändern, an die Sie den Patch senden, möglicherweise den Maintainer oder die verantwortliche Person mit in CC zu nehmen und ihn zu versenden.
Sie können die Patches auch über einen SMTP-Server senden. Wie zuvor können Sie jeden Wert separat mit einer Reihe von git config-Befehlen festlegen oder sie manuell im Abschnitt sendemail in Ihrer Datei ~/.gitconfig hinzufügen
[sendemail]
smtpencryption = tls
smtpserver = smtp.gmail.com
smtpuser = user@gmail.com
smtpserverport = 587Danach können Sie git send-email verwenden, um Ihre Patches zu senden
$ git send-email *.patch
0001-add-limit-to-log-function.patch
0002-increase-log-output-to-30-from-25.patch
Who should the emails appear to be from? [Jessica Smith <jessica@example.com>]
Emails will be sent from: Jessica Smith <jessica@example.com>
Who should the emails be sent to? jessica@example.com
Message-ID to be used as In-Reply-To for the first email? yDann gibt Git für jeden Patch, den Sie senden, eine Menge Protokollinformationen aus, die etwa so aussehen
(mbox) Adding cc: Jessica Smith <jessica@example.com> from
\line 'From: Jessica Smith <jessica@example.com>'
OK. Log says:
Sendmail: /usr/sbin/sendmail -i jessica@example.com
From: Jessica Smith <jessica@example.com>
To: jessica@example.com
Subject: [PATCH 1/2] Add limit to log function
Date: Sat, 30 May 2009 13:29:15 -0700
Message-Id: <1243715356-61726-1-git-send-email-jessica@example.com>
X-Mailer: git-send-email 1.6.2.rc1.20.g8c5b.dirty
In-Reply-To: <y>
References: <y>
Result: OK|
Tipp
|
Für Hilfe bei der Konfiguration Ihres Systems und Ihrer E-Mail, weitere Tipps und Tricks sowie eine Sandbox zum Senden eines Test-Patches per E-Mail besuchen Sie git-send-email.io. |
Zusammenfassung
In diesem Abschnitt haben wir mehrere Workflows behandelt und die Unterschiede zwischen der Arbeit als Teil eines kleinen Teams an Closed-Source-Projekten und der Mitarbeit an einem großen öffentlichen Projekt besprochen. Sie wissen jetzt, dass Sie vor dem Committen auf Whitespace-Fehler prüfen und eine großartige Commit-Nachricht schreiben können. Sie haben gelernt, wie man Patches formatiert und sie per E-Mail an eine Entwickler-Mailingliste sendet. Der Umgang mit Merges wurde ebenfalls im Kontext der verschiedenen Workflows behandelt. Sie sind nun gut darauf vorbereitet, an jedem Projekt zusammenzuarbeiten.
Als Nächstes sehen Sie, wie die andere Seite der Medaille funktioniert: die Wartung eines Git-Projekts. Sie lernen, wie man ein wohlwollender Diktator oder Integrationsmanager wird.