
-
1. Erste Schritte
- 1.1 Über Versionskontrolle
- 1.2 Eine kurze Geschichte von Git
- 1.3 Was ist Git?
- 1.4 Die Kommandozeile
- 1.5 Git installieren
- 1.6 Erstmalige Git-Einrichtung
- 1.7 Hilfe bekommen
- 1.8 Zusammenfassung
-
2. Git Grundlagen
-
3. Git Branching
- 3.1 Branches im Überblick
- 3.2 Grundlegendes Branching und Merging
- 3.3 Branch-Management
- 3.4 Branching-Workflows
- 3.5 Remote-Branches
- 3.6 Rebasing
- 3.7 Zusammenfassung
-
4. Git auf dem Server
- 4.1 Die Protokolle
- 4.2 Git auf einem Server einrichten
- 4.3 Generieren Ihres SSH-Public-Keys
- 4.4 Einrichten des Servers
- 4.5 Git Daemon
- 4.6 Smart HTTP
- 4.7 GitWeb
- 4.8 GitLab
- 4.9 Drittanbieter-Hosting-Optionen
- 4.10 Zusammenfassung
-
5. Verteiltes Git
-
6. GitHub
-
7. Git-Werkzeuge
- 7.1 Revisionsauswahl
- 7.2 Interaktives Staging
- 7.3 Stashing und Bereinigen
- 7.4 Ihre Arbeit signieren
- 7.5 Suchen
- 7.6 Historie umschreiben
- 7.7 Reset entmystifiziert
- 7.8 Fortgeschrittenes Merging
- 7.9 Rerere
- 7.10 Debugging mit Git
- 7.11 Submodule
- 7.12 Bundling
- 7.13 Ersetzen
- 7.14 Credential-Speicher
- 7.15 Zusammenfassung
-
8. Git anpassen
-
9. Git und andere Systeme
- 9.1 Git als Client
- 9.2 Migration zu Git
- 9.3 Zusammenfassung
-
10. Git-Interna
- 10.1 Plumbing und Porcelain
- 10.2 Git-Objekte
- 10.3 Git-Referenzen
- 10.4 Packfiles
- 10.5 Die Refspec
- 10.6 Übertragungsprotokolle
- 10.7 Wartung und Datenwiederherstellung
- 10.8 Umgebungsvariablen
- 10.9 Zusammenfassung
-
Anhang A: Git in anderen Umgebungen
- A1.1 Grafische Oberflächen
- A1.2 Git in Visual Studio
- A1.3 Git in Visual Studio Code
- A1.4 Git in IntelliJ / PyCharm / WebStorm / PhpStorm / RubyMine
- A1.5 Git in Sublime Text
- A1.6 Git in Bash
- A1.7 Git in Zsh
- A1.8 Git in PowerShell
- A1.9 Zusammenfassung
-
Anhang B: Git in Ihre Anwendungen einbetten
- A2.1 Kommandozeilen-Git
- A2.2 Libgit2
- A2.3 JGit
- A2.4 go-git
- A2.5 Dulwich
-
Anhang C: Git-Befehle
- A3.1 Einrichtung und Konfiguration
- A3.2 Projekte abrufen und erstellen
- A3.3 Grundlegendes Snapshotting
- A3.4 Branching und Merging
- A3.5 Projekte teilen und aktualisieren
- A3.6 Inspektion und Vergleich
- A3.7 Debugging
- A3.8 Patching
- A3.9 E-Mail
- A3.10 Externe Systeme
- A3.11 Administration
- A3.12 Plumbing-Befehle
1.3 Getting Started - Was ist Git?
Was ist Git?
Also, was ist Git in Kürze? Dies ist ein wichtiger Abschnitt, den Sie aufnehmen sollten, denn wenn Sie verstehen, was Git ist und die Grundlagen, wie es funktioniert, dann wird die effektive Nutzung von Git wahrscheinlich viel einfacher für Sie sein. Wenn Sie Git lernen, versuchen Sie, Ihre Gedanken von den Dingen, die Sie vielleicht über andere VCS (Versionskontrollsysteme) wissen, wie CVS, Subversion oder Perforce, zu befreien – dies wird Ihnen helfen, subtile Verwirrung bei der Verwendung des Tools zu vermeiden. Obwohl die Benutzeroberfläche von Git diesen anderen VCS ziemlich ähnlich ist, speichert und denkt Git Informationen auf eine sehr andere Weise, und das Verständnis dieser Unterschiede wird Ihnen helfen, Verwirrung bei der Nutzung zu vermeiden.
Snapshots statt Unterschiede
Der Hauptunterschied zwischen Git und jedem anderen VCS (einschließlich Subversion und ähnlichen Systemen) liegt in der Art und Weise, wie Git seine Daten betrachtet. Konzeptionell speichern die meisten anderen Systeme Informationen als eine Liste von dateibasierten Änderungen. Diese anderen Systeme (CVS, Subversion, Perforce und so weiter) betrachten die von ihnen gespeicherten Informationen als eine Menge von Dateien und die Änderungen, die im Laufe der Zeit an jeder Datei vorgenommen wurden (dies wird üblicherweise als delta-basierte Versionskontrolle beschrieben).
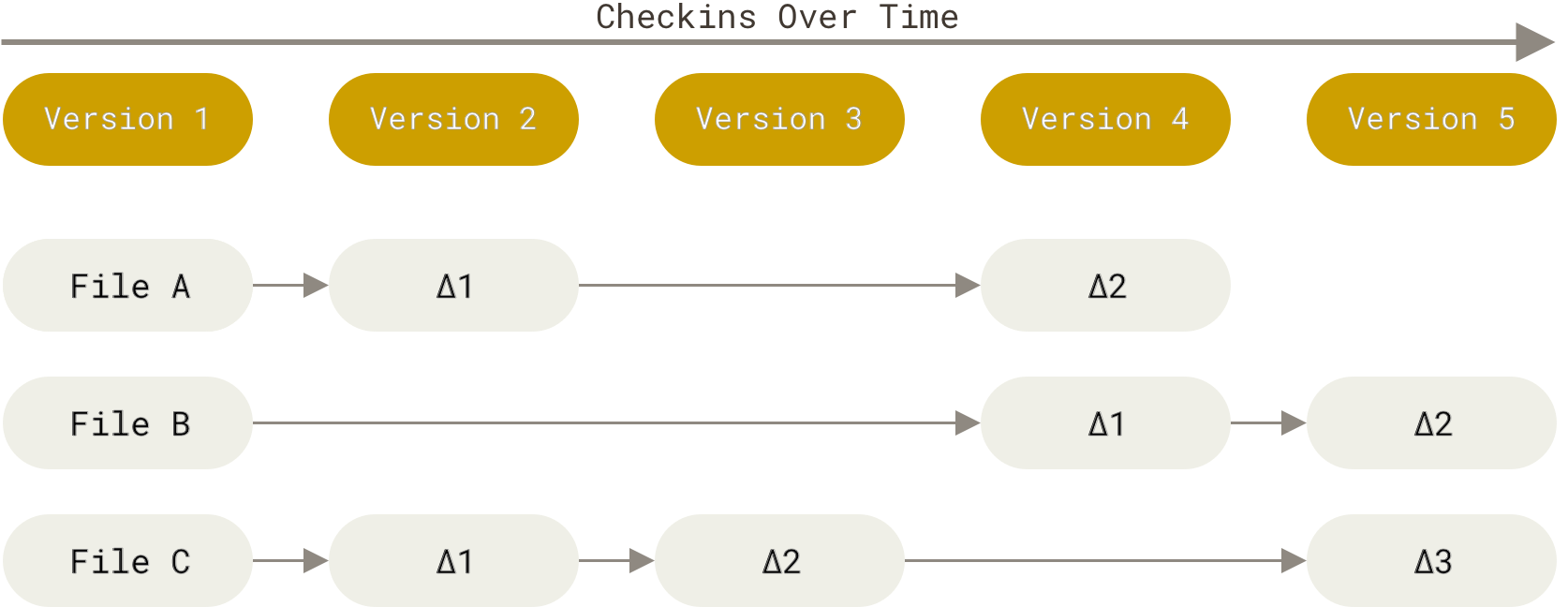
Git denkt oder speichert seine Daten nicht auf diese Weise. Stattdessen denkt Git über seine Daten eher wie eine Reihe von Schnappschüssen eines Miniatur-Dateisystems. Mit Git nimmt Git jedes Mal, wenn Sie den Zustand Ihres Projekts committen oder speichern, im Grunde ein Bild davon auf, wie alle Ihre Dateien in diesem Moment aussehen, und speichert eine Referenz auf diesen Schnappschuss. Um effizient zu sein, speichert Git eine Datei nicht erneut, wenn sie sich nicht geändert hat, sondern nur einen Link zur vorherigen identischen Datei, die es bereits gespeichert hat. Git denkt über seine Daten eher wie ein Stream von Schnappschüssen.
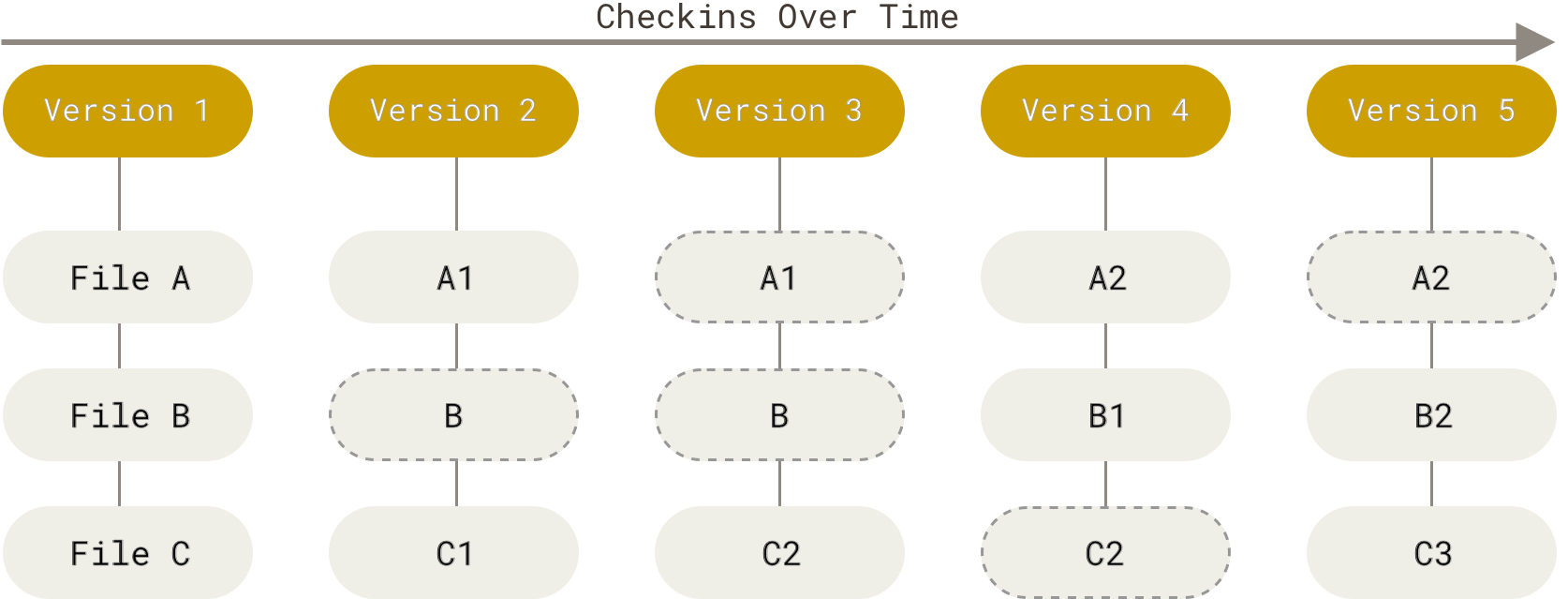
Dies ist ein wichtiger Unterschied zwischen Git und fast allen anderen VCS. Er veranlasst Git, fast jeden Aspekt der Versionskontrolle neu zu überdenken, den die meisten anderen Systeme von der vorherigen Generation übernommen haben. Das macht Git eher zu einem Mini-Dateisystem mit unglaublich leistungsstarken Werkzeugen, anstatt nur zu einem VCS. Wir werden einige der Vorteile untersuchen, die Sie durch die Betrachtung Ihrer Daten auf diese Weise erzielen, wenn wir uns mit Git-Branching in Git-Branching befassen.
Fast alle Operationen sind lokal
Die meisten Operationen in Git benötigen nur lokale Dateien und Ressourcen für den Betrieb – im Allgemeinen werden keine Informationen von einem anderen Computer in Ihrem Netzwerk benötigt. Wenn Sie an ein CVCS gewöhnt sind, bei dem die meisten Operationen mit Netzwerk-Latenz verbunden sind, wird Sie dieser Aspekt von Git denken lassen, dass die Götter der Geschwindigkeit Git mit überirdischen Kräften gesegnet haben. Da Sie die gesamte Historie des Projekts direkt auf Ihrer lokalen Festplatte haben, scheinen die meisten Operationen fast augenblicklich zu erfolgen.
Um beispielsweise die Historie des Projekts anzuzeigen, muss Git nicht auf den Server gehen, um die Historie abzurufen und anzuzeigen – es liest sie einfach direkt aus Ihrer lokalen Datenbank. Das bedeutet, dass Sie die Projekt-Historie fast sofort sehen. Wenn Sie die Änderungen sehen möchten, die zwischen der aktuellen Version einer Datei und der Datei von vor einem Monat eingeführt wurden, kann Git die Datei von vor einem Monat nachschlagen und eine lokale Differenzberechnung durchführen, anstatt entweder einen Remote-Server damit zu beauftragen oder eine ältere Version der Datei vom Remote-Server abzurufen, um sie lokal zu verarbeiten.
Dies bedeutet auch, dass es sehr wenig gibt, was Sie nicht tun können, wenn Sie offline oder nicht per VPN verbunden sind. Wenn Sie in ein Flugzeug oder einen Zug steigen und ein wenig arbeiten möchten, können Sie glücklich committen (in Ihre lokale Kopie, erinnern Sie sich?) bis Sie eine Netzwerkverbindung haben, um hochzuladen. Wenn Sie nach Hause gehen und Ihr VPN-Client nicht richtig funktioniert, können Sie trotzdem arbeiten. In vielen anderen Systemen ist dies entweder unmöglich oder mühsam. In Perforce zum Beispiel können Sie nicht viel tun, wenn Sie nicht mit dem Server verbunden sind; in Subversion und CVS können Sie Dateien bearbeiten, aber Sie können keine Änderungen in Ihrer Datenbank committen (weil Ihre Datenbank offline ist). Dies scheint vielleicht keine große Sache zu sein, aber Sie werden überrascht sein, wie viel Unterschied es machen kann.
Git hat Integrität
Alles in Git wird vor der Speicherung per Checksumme überprüft und dann über diese Checksumme referenziert. Das bedeutet, dass es unmöglich ist, den Inhalt einer Datei oder eines Verzeichnisses zu ändern, ohne dass Git davon Kenntnis erhält. Diese Funktionalität ist in Git auf den untersten Ebenen integriert und integraler Bestandteil seiner Philosophie. Sie können keine Informationen während der Übertragung verlieren oder Dateikorruption erleiden, ohne dass Git dies erkennen kann.
Der Mechanismus, den Git für diese Checksummen verwendet, wird als SHA-1-Hash bezeichnet. Dies ist eine 40-stellige Zeichenkette, die aus hexadezimalen Zeichen (0-9 und a-f) besteht und basierend auf dem Inhalt einer Datei oder Verzeichnisstruktur in Git berechnet wird. Ein SHA-1-Hash sieht ungefähr so aus
24b9da6552252987aa493b52f8696cd6d3b00373Sie werden diese Hash-Werte überall in Git sehen, weil es sie so häufig verwendet. Tatsächlich speichert Git alles in seiner Datenbank nicht nach Dateinamen, sondern nach dem Hash-Wert seines Inhalts.
Git fügt Daten im Allgemeinen nur hinzu
Wenn Sie Aktionen in Git durchführen, fügen fast alle davon nur Daten zur Git-Datenbank hinzu. Es ist schwierig, das System dazu zu bringen, etwas zu tun, das nicht rückgängig gemacht werden kann, oder es dazu zu bringen, Daten auf irgendeine Weise zu löschen. Wie bei jedem VCS können Sie Änderungen verlieren oder vermasseln, die Sie noch nicht committet haben, aber nachdem Sie einen Schnappschuss in Git committet haben, ist es sehr schwierig, ihn zu verlieren, besonders wenn Sie Ihre Datenbank regelmäßig in ein anderes Repository pushen.
Das macht die Nutzung von Git zu einer Freude, denn wir wissen, dass wir experimentieren können, ohne die Gefahr, etwas ernsthaft zu vermasseln. Für einen detaillierteren Einblick, wie Git seine Daten speichert und wie Sie scheinbar verlorene Daten wiederherstellen können, siehe Dinge rückgängig machen.
Die drei Zustände
Achten Sie jetzt aufmerksam hin – dies ist das Wichtigste, das Sie sich über Git merken sollten, wenn Sie möchten, dass der Rest Ihres Lernprozesses reibungslos verläuft. Git hat drei Hauptzustände, in denen sich Ihre Dateien befinden können: modifiziert, gestaged und committet
-
Modifiziert bedeutet, dass Sie die Datei geändert haben, sie aber noch nicht in Ihre Datenbank committet haben.
-
Gestaged bedeutet, dass Sie eine modifizierte Datei in ihrer aktuellen Version markiert haben, um sie in Ihren nächsten Commit-Schnappschuss aufzunehmen.
-
Committed bedeutet, dass die Daten sicher in Ihrer lokalen Datenbank gespeichert sind.
Dies führt uns zu den drei Hauptbereichen eines Git-Projekts: dem Arbeitsverzeichnis, dem Staging-Bereich und dem Git-Verzeichnis.
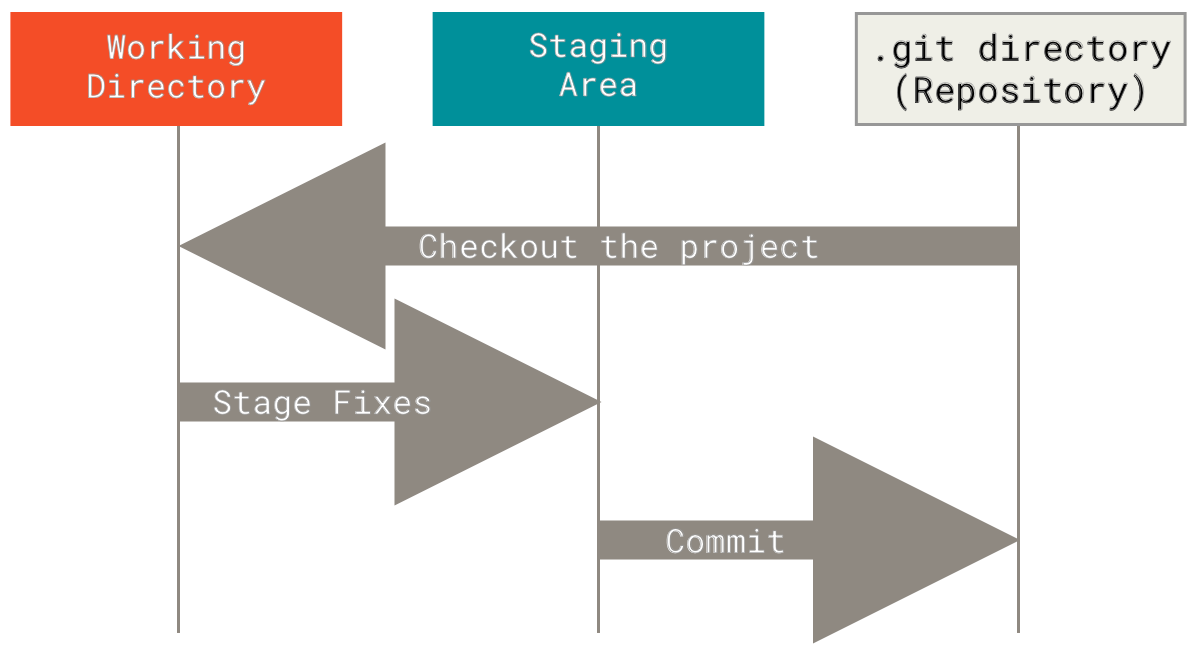
Das Arbeitsverzeichnis ist ein einzelner Checkout einer Version des Projekts. Diese Dateien werden aus der komprimierten Datenbank im Git-Verzeichnis extrahiert und auf die Festplatte gelegt, damit Sie sie verwenden oder ändern können.
Der Staging-Bereich ist eine Datei, die im Allgemeinen in Ihrem Git-Verzeichnis enthalten ist und Informationen darüber speichert, was in Ihren nächsten Commit aufgenommen wird. Sein technischer Name im Git-Jargon ist "Index", aber die Phrase "Staging-Bereich" funktioniert genauso gut.
Das Git-Verzeichnis ist der Ort, an dem Git die Metadaten und die Objektdatenbank für Ihr Projekt speichert. Dies ist der wichtigste Teil von Git und wird kopiert, wenn Sie ein Repository von einem anderen Computer klonen.
Der grundlegende Git-Workflow sieht ungefähr so aus
-
Sie modifizieren Dateien in Ihrem Arbeitsverzeichnis.
-
Sie stagen selektiv nur die Änderungen, die Teil Ihres nächsten Commits sein sollen, was nur diese Änderungen zum Staging-Bereich hinzufügt.
-
Sie führen einen Commit durch, der die Dateien, wie sie sich im Staging-Bereich befinden, nimmt und diesen Schnappschuss dauerhaft in Ihrem Git-Verzeichnis speichert.
Wenn eine bestimmte Version einer Datei im Git-Verzeichnis vorhanden ist, gilt sie als committet. Wenn sie modifiziert und zum Staging-Bereich hinzugefügt wurde, ist sie gestaged. Und wenn sie geändert wurde, seit sie ausgecheckt wurde, aber nicht gestaged wurde, ist sie modifiziert. In Git-Grundlagen lernen Sie mehr über diese Zustände und wie Sie diese nutzen oder den gestagten Teil ganz überspringen können.