
-
1. Erste Schritte
- 1.1 Über Versionskontrolle
- 1.2 Eine kurze Geschichte von Git
- 1.3 Was ist Git?
- 1.4 Die Kommandozeile
- 1.5 Git installieren
- 1.6 Erstmalige Git-Einrichtung
- 1.7 Hilfe bekommen
- 1.8 Zusammenfassung
-
2. Git Grundlagen
-
3. Git Branching
- 3.1 Branches im Überblick
- 3.2 Grundlegendes Branching und Merging
- 3.3 Branch-Management
- 3.4 Branching-Workflows
- 3.5 Remote-Branches
- 3.6 Rebasing
- 3.7 Zusammenfassung
-
4. Git auf dem Server
- 4.1 Die Protokolle
- 4.2 Git auf einem Server einrichten
- 4.3 Generieren Ihres SSH-Public-Keys
- 4.4 Einrichten des Servers
- 4.5 Git Daemon
- 4.6 Smart HTTP
- 4.7 GitWeb
- 4.8 GitLab
- 4.9 Drittanbieter-Hosting-Optionen
- 4.10 Zusammenfassung
-
5. Verteiltes Git
-
6. GitHub
-
7. Git-Werkzeuge
- 7.1 Revisionsauswahl
- 7.2 Interaktives Staging
- 7.3 Stashing und Bereinigen
- 7.4 Ihre Arbeit signieren
- 7.5 Suchen
- 7.6 Historie umschreiben
- 7.7 Reset Demystified
- 7.8 Fortgeschrittenes Merging
- 7.9 Rerere
- 7.10 Debugging mit Git
- 7.11 Submodule
- 7.12 Bundling
- 7.13 Ersetzen
- 7.14 Credential-Speicher
- 7.15 Zusammenfassung
-
8. Git anpassen
-
9. Git und andere Systeme
- 9.1 Git als Client
- 9.2 Migration zu Git
- 9.3 Zusammenfassung
-
10. Git-Interna
- 10.1 Plumbing und Porcelain
- 10.2 Git-Objekte
- 10.3 Git-Referenzen
- 10.4 Packfiles
- 10.5 Die Refspec
- 10.6 Übertragungsprotokolle
- 10.7 Wartung und Datenwiederherstellung
- 10.8 Umgebungsvariablen
- 10.9 Zusammenfassung
-
Anhang A: Git in anderen Umgebungen
- A1.1 Grafische Oberflächen
- A1.2 Git in Visual Studio
- A1.3 Git in Visual Studio Code
- A1.4 Git in IntelliJ / PyCharm / WebStorm / PhpStorm / RubyMine
- A1.5 Git in Sublime Text
- A1.6 Git in Bash
- A1.7 Git in Zsh
- A1.8 Git in PowerShell
- A1.9 Zusammenfassung
-
Anhang B: Git in Ihre Anwendungen einbetten
- A2.1 Kommandozeilen-Git
- A2.2 Libgit2
- A2.3 JGit
- A2.4 go-git
- A2.5 Dulwich
-
Anhang C: Git-Befehle
- A3.1 Einrichtung und Konfiguration
- A3.2 Projekte abrufen und erstellen
- A3.3 Grundlegendes Snapshotting
- A3.4 Branching und Merging
- A3.5 Projekte teilen und aktualisieren
- A3.6 Inspektion und Vergleich
- A3.7 Debugging
- A3.8 Patching
- A3.9 E-Mail
- A3.10 Externe Systeme
- A3.11 Administration
- A3.12 Plumbing-Befehle
7.7 Git Tools - Reset Demystified
Reset Demystified
Bevor wir zu spezialisierteren Werkzeugen übergehen, sprechen wir über die Git-Befehle reset und checkout. Diese Befehle gehören zu den verwirrendsten Teilen von Git, wenn man ihnen zum ersten Mal begegnet. Sie tun so viele Dinge, dass es hoffnungslos erscheint, sie tatsächlich zu verstehen und richtig anzuwenden. Dafür empfehlen wir eine einfache Metapher.
Die drei Bäume
Ein einfacherer Weg, über reset und checkout nachzudenken, ist das mentale Modell, dass Git ein Inhaltsverwalter von drei verschiedenen Bäumen ist. Mit "Baum" meinen wir hier eigentlich "Sammlung von Dateien", nicht speziell die Datenstruktur. Es gibt einige Fälle, in denen der Index nicht genau wie ein Baum funktioniert, aber für unsere Zwecke ist es einfacher, ihn vorerst so zu betrachten.
Git als System verwaltet und manipuliert im normalen Betrieb drei Bäume
| Baum | Rolle |
|---|---|
HEAD |
Snapshot des letzten Commits, nächster Elternknoten |
Index |
Vorgeschlagener Snapshot des nächsten Commits |
Arbeitsverzeichnis |
Sandbox |
Der HEAD
HEAD ist der Zeiger auf die aktuelle Branch-Referenz, die wiederum ein Zeiger auf den letzten Commit ist, der auf diesem Branch erstellt wurde. Das bedeutet, HEAD ist der Elternknoten des nächsten Commits, der erstellt wird. Im Allgemeinen ist es am einfachsten, HEAD als den Snapshot **Ihres letzten Commits auf diesem Branch** zu betrachten.
Tatsächlich ist es ziemlich einfach zu sehen, wie dieser Snapshot aussieht. Hier ist ein Beispiel für den Abruf der tatsächlichen Verzeichnisliste und der SHA-1-Prüfsummen für jede Datei im HEAD-Snapshot
$ git cat-file -p HEAD
tree cfda3bf379e4f8dba8717dee55aab78aef7f4daf
author Scott Chacon 1301511835 -0700
committer Scott Chacon 1301511835 -0700
initial commit
$ git ls-tree -r HEAD
100644 blob a906cb2a4a904a152... README
100644 blob 8f94139338f9404f2... Rakefile
040000 tree 99f1a6d12cb4b6f19... libDie Git-Befehle cat-file und ls-tree sind "Plumbing"-Befehle, die für grundlegendere Dinge verwendet werden und nicht wirklich im täglichen Gebrauch vorkommen, aber sie helfen uns zu verstehen, was hier vor sich geht.
Der Index
Der *Index* ist Ihr **vorgeschlagener nächster Commit**. Wir haben dieses Konzept auch als Git's "Staging Area" bezeichnet, da Git dies betrachtet, wenn Sie git commit ausführen.
Git füllt diesen Index mit einer Liste aller Dateiinhalte, die zuletzt in Ihr Arbeitsverzeichnis ausgecheckt wurden, und wie sie aussahen, als sie ursprünglich ausgecheckt wurden. Sie ersetzen dann einige dieser Dateien durch neue Versionen und git commit wandelt dies in den Baum für einen neuen Commit um.
$ git ls-files -s
100644 a906cb2a4a904a152e80877d4088654daad0c859 0 README
100644 8f94139338f9404f26296befa88755fc2598c289 0 Rakefile
100644 47c6340d6459e05787f644c2447d2595f5d3a54b 0 lib/simplegit.rbAuch hier verwenden wir git ls-files, einen eher im Hintergrund ablaufenden Befehl, der Ihnen zeigt, wie Ihr Index derzeit aussieht.
Der Index ist technisch gesehen keine Baumstruktur – er ist tatsächlich als abgeflachte Manifest-Datei implementiert –, aber für unsere Zwecke ist er nah genug dran.
Das Arbeitsverzeichnis
Schließlich haben Sie Ihr *Arbeitsverzeichnis* (auch oft als "Working Tree" bezeichnet). Die beiden anderen Bäume speichern ihre Inhalte auf effiziente, aber unbequeme Weise im .git-Ordner. Das Arbeitsverzeichnis entpackt sie in tatsächliche Dateien, was die Bearbeitung für Sie viel einfacher macht. Betrachten Sie das Arbeitsverzeichnis als eine **Sandbox**, in der Sie Änderungen ausprobieren können, bevor Sie sie in Ihre Staging Area (Index) und dann in die Historie committen.
$ tree
.
├── README
├── Rakefile
└── lib
└── simplegit.rb
1 directory, 3 filesDer Workflow
Git's typischer Workflow besteht darin, Snapshots Ihres Projekts in aufeinander aufbauend besseren Zuständen zu speichern, indem diese drei Bäume manipuliert werden.
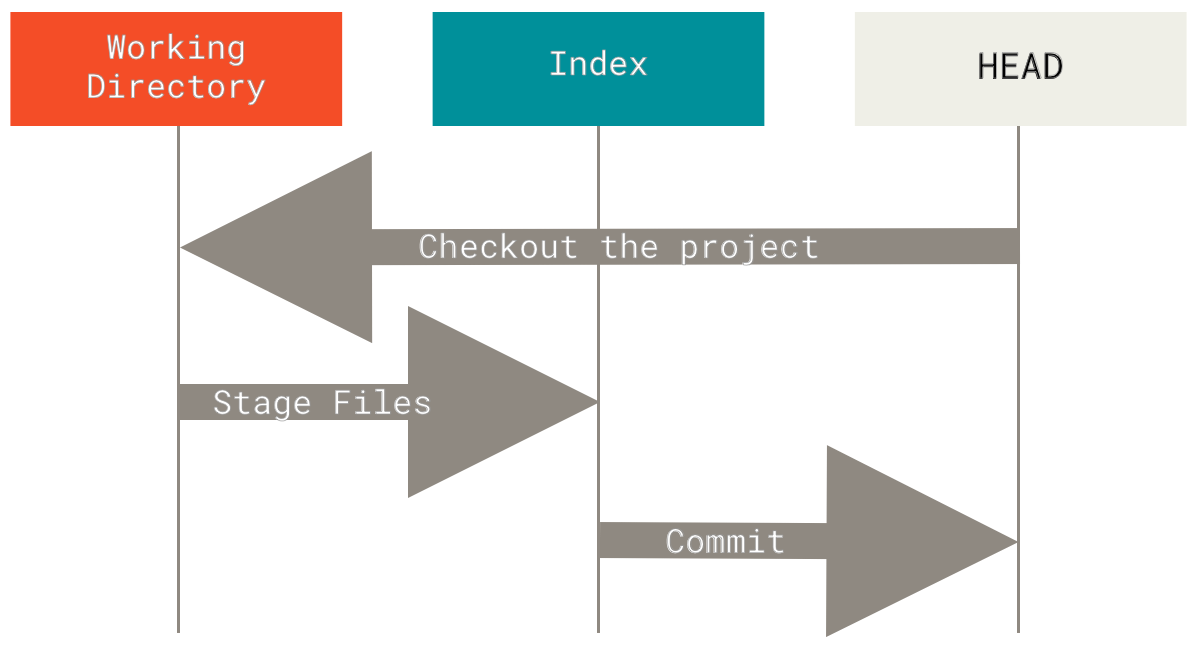
Visualisieren wir diesen Prozess: Nehmen wir an, Sie gehen in ein neues Verzeichnis mit einer einzelnen Datei. Wir nennen diese Version **v1** der Datei und kennzeichnen sie in Blau. Jetzt führen wir git init aus, was ein Git-Repository mit einer HEAD-Referenz erstellt, die auf den ungeborenen master-Branch zeigt.
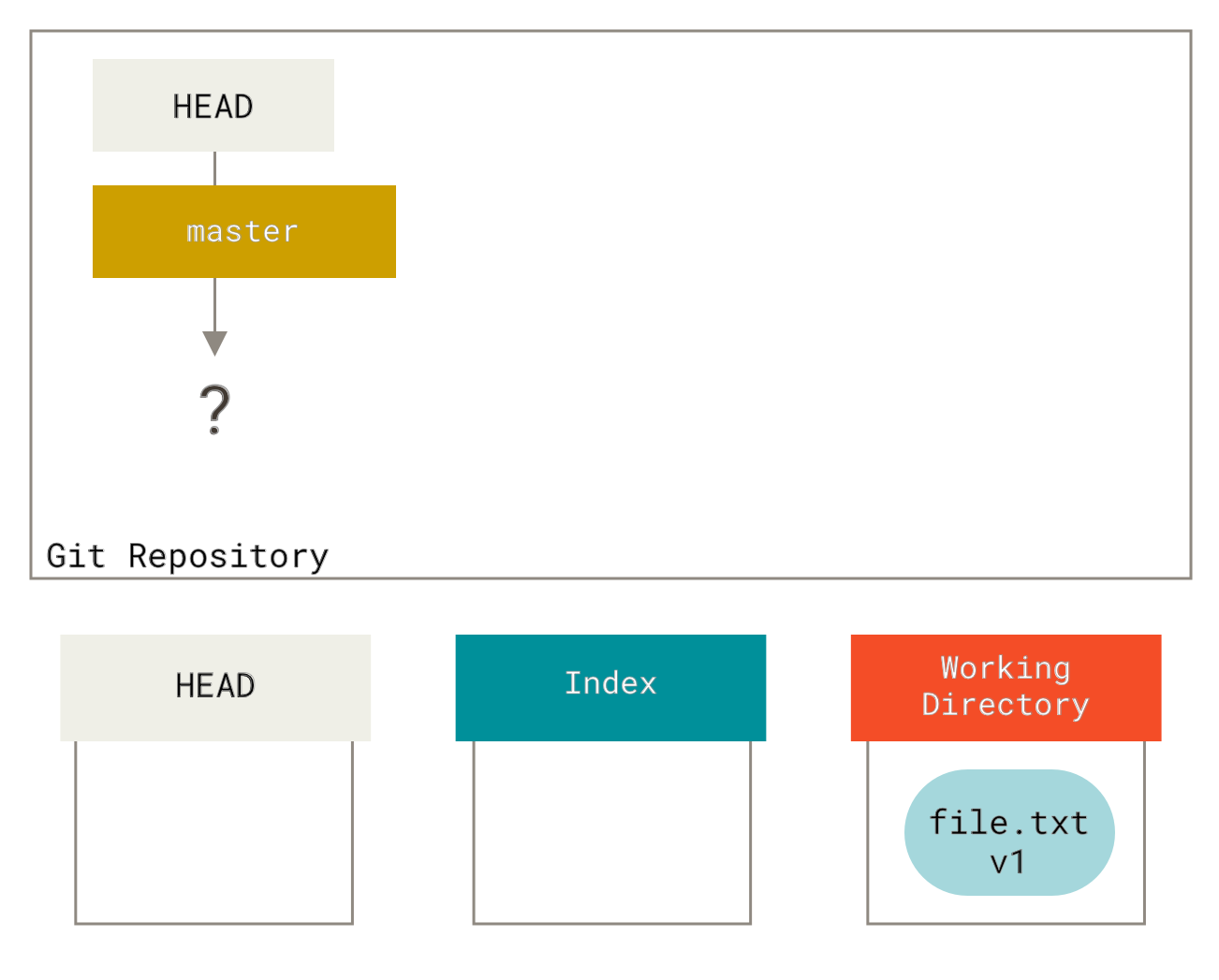
Zu diesem Zeitpunkt enthält nur der Baum des Arbeitsverzeichnisses Inhalt.
Jetzt wollen wir diese Datei committen, also verwenden wir git add, um den Inhalt aus dem Arbeitsverzeichnis zu nehmen und in den Index zu kopieren.
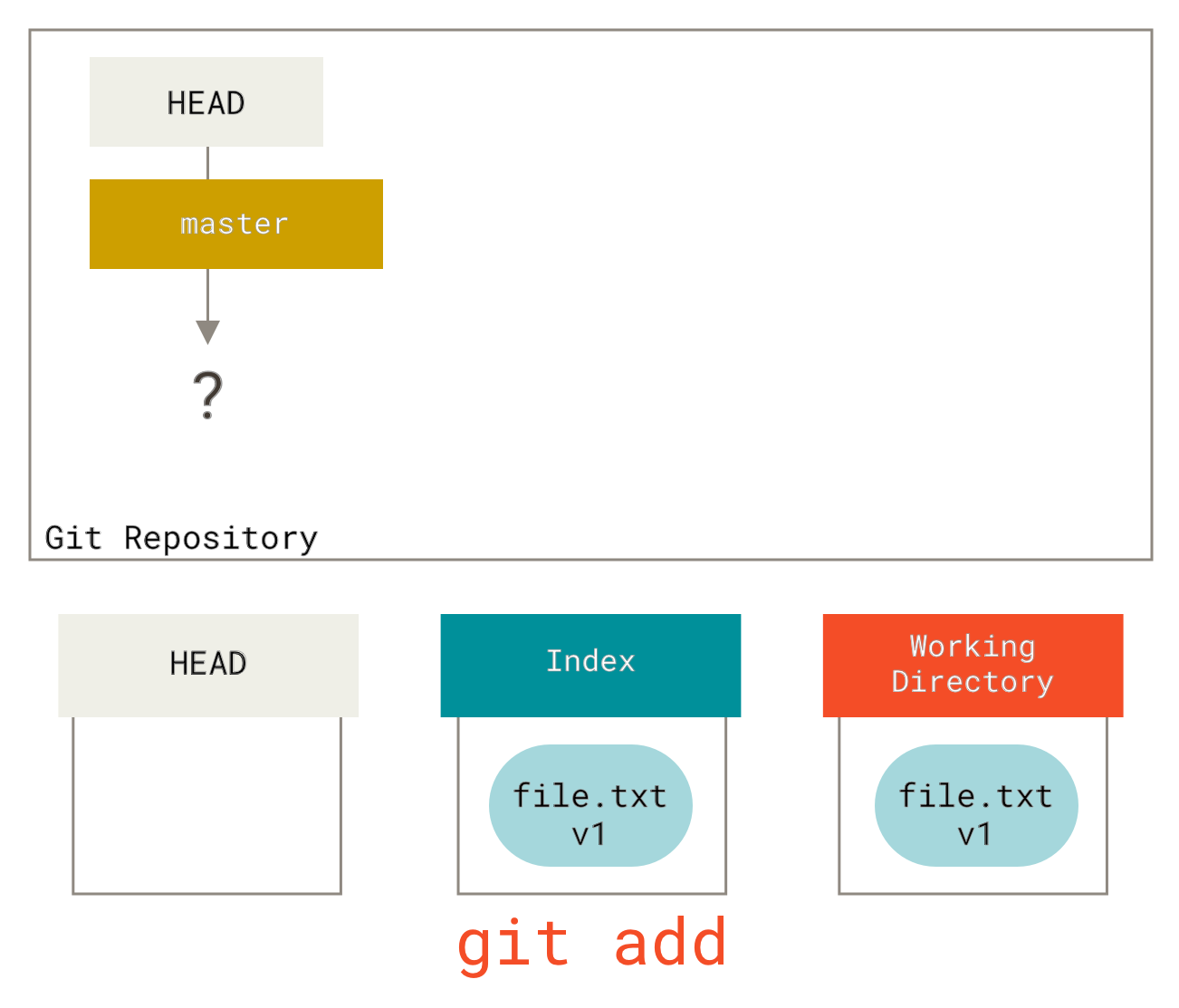
git add in den Index kopiertDann führen wir git commit aus, was den Inhalt des Index nimmt und ihn als dauerhaften Snapshot speichert, ein Commit-Objekt erstellt, das auf diesen Snapshot zeigt, und master aktualisiert, sodass es auf diesen Commit zeigt.

git commitWenn wir git status ausführen, sehen wir keine Änderungen, da alle drei Bäume gleich sind.
Jetzt wollen wir diese Datei ändern und committen. Wir gehen den gleichen Prozess durch; zuerst ändern wir die Datei in unserem Arbeitsverzeichnis. Nennen wir dies **v2** der Datei und kennzeichnen sie in Rot.
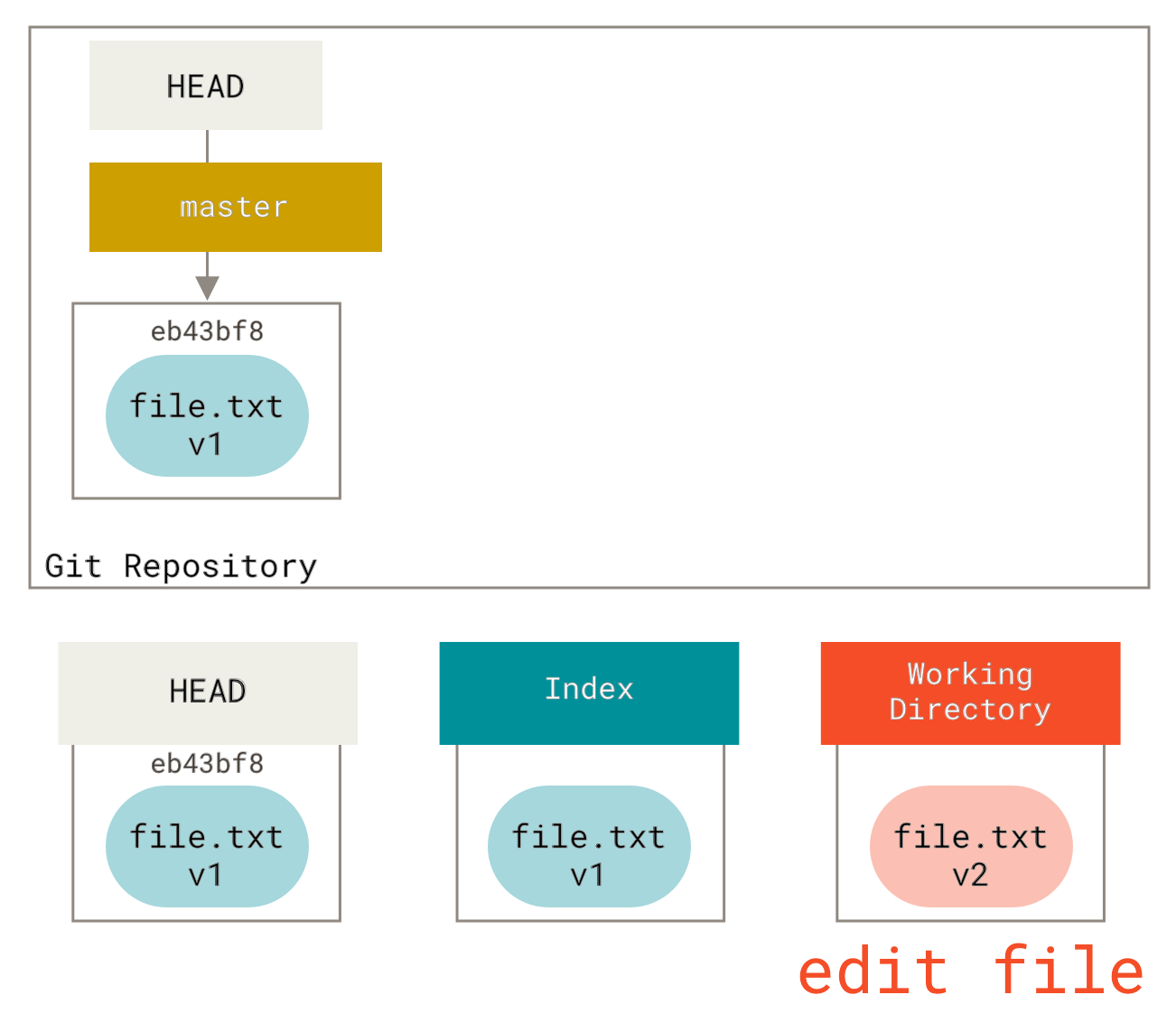
Wenn wir jetzt git status ausführen, sehen wir die Datei in Rot als "Änderungen nicht für den Commit vorbereitet", da dieser Eintrag zwischen dem Index und dem Arbeitsverzeichnis abweicht. Als nächstes führen wir git add darauf aus, um sie in unseren Index zu übertragen.
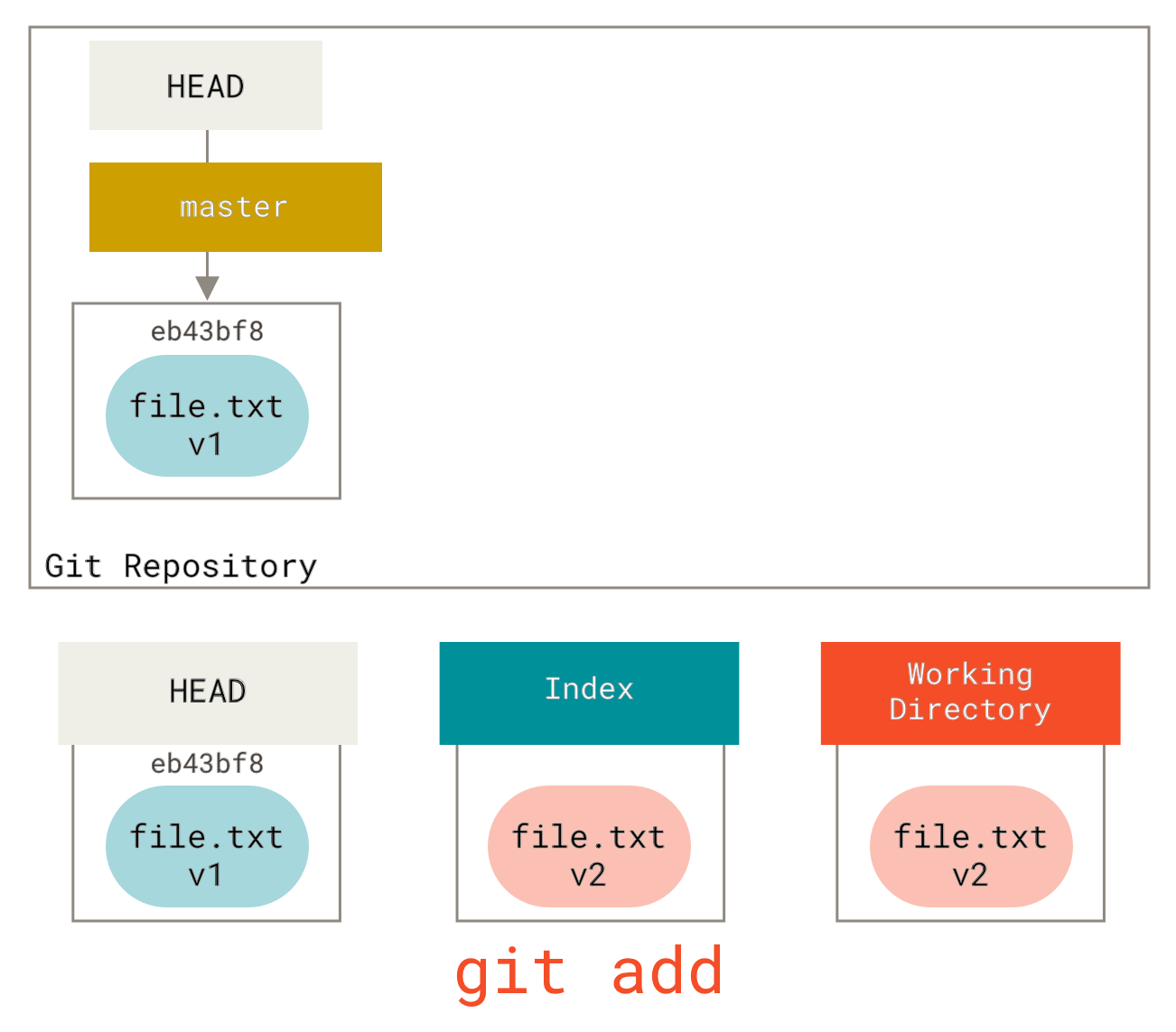
Zu diesem Zeitpunkt, wenn wir git status ausführen, sehen wir die Datei in Grün unter "Änderungen zum Committen", da der Index und HEAD abweichen – das heißt, unser vorgeschlagener nächster Commit unterscheidet sich nun von unserem letzten Commit. Schließlich führen wir git commit aus, um den Commit abzuschließen.
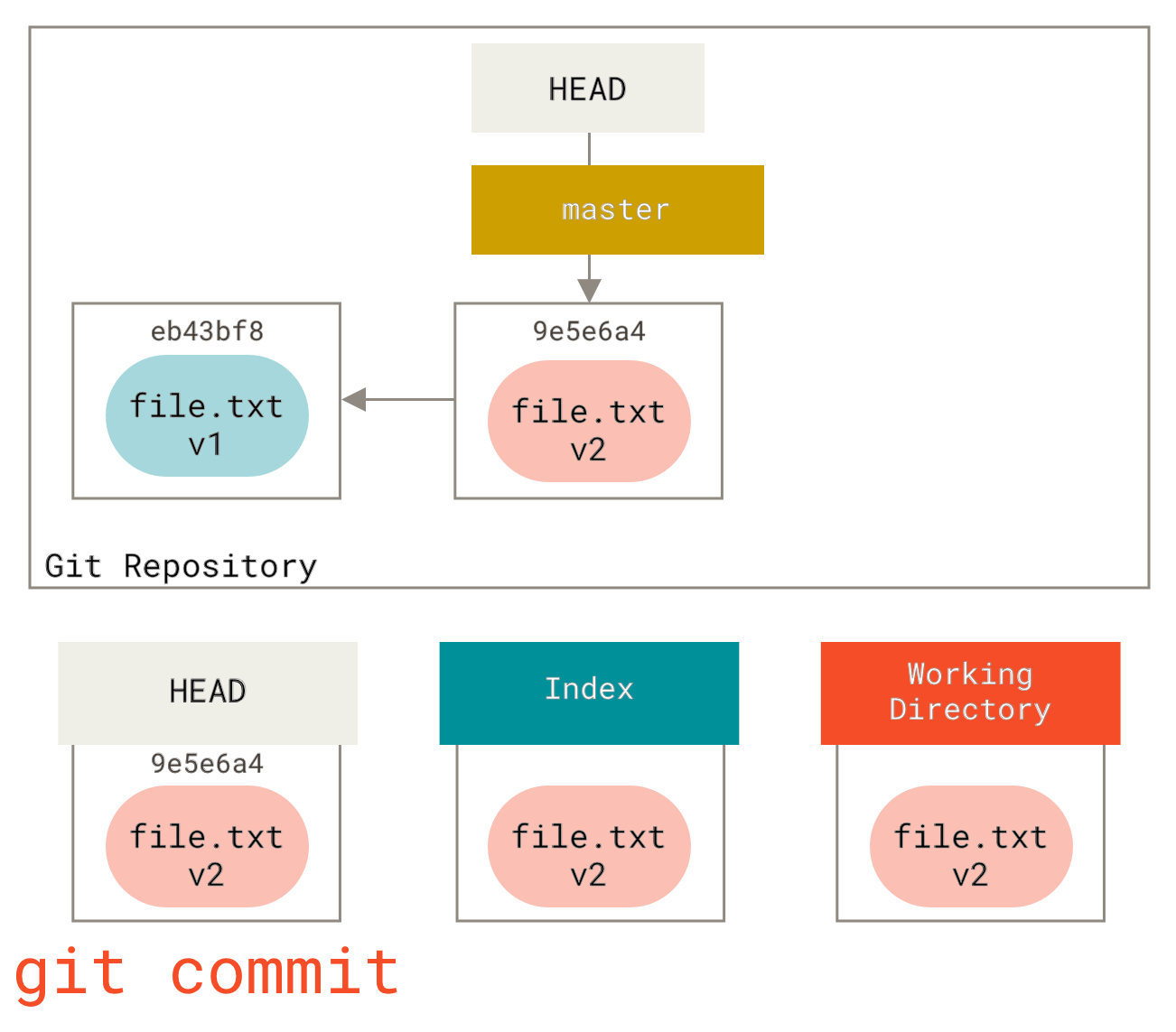
git commit mit geänderter DateiNun gibt uns git status keine Ausgabe mehr, da alle drei Bäume wieder gleich sind.
Das Wechseln von Branches oder das Klonen durchläuft einen ähnlichen Prozess. Wenn Sie einen Branch auschecken, ändert dies **HEAD**, sodass er auf die neue Branch-Referenz zeigt, füllt Ihren **Index** mit dem Snapshot dieses Commits und kopiert dann den Inhalt des **Index** in Ihr **Arbeitsverzeichnis**.
Die Rolle von Reset
Der Befehl reset ergibt in diesem Kontext mehr Sinn.
Für die Zwecke dieser Beispiele sagen wir, dass wir file.txt erneut geändert und ein drittes Mal committet haben. Unsere Historie sieht also jetzt so aus
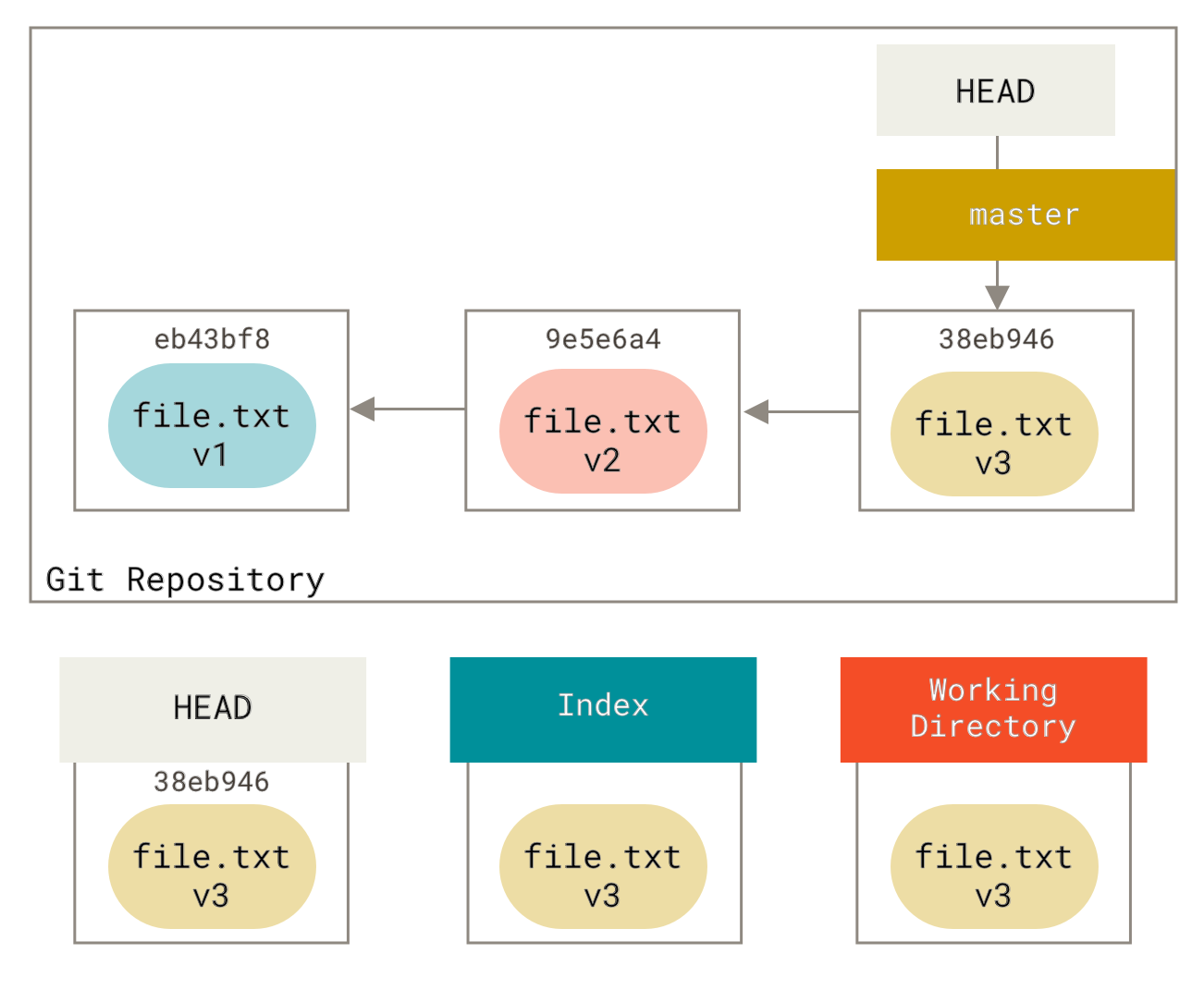
Gehen wir nun genau durch, was reset tut, wenn Sie es aufrufen. Es manipuliert diese drei Bäume direkt auf eine einfache und vorhersagbare Weise. Es führt bis zu drei grundlegende Operationen durch.
Schritt 1: HEAD bewegen
Das Erste, was reset tut, ist, zu bewegen, worauf HEAD zeigt. Das ist nicht dasselbe wie HEAD selbst zu ändern (was checkout tut); reset bewegt den Branch, auf den HEAD zeigt. Das bedeutet, wenn HEAD auf den master-Branch gesetzt ist (d.h. Sie sind gerade auf dem master-Branch), wird der Aufruf von git reset 9e5e6a4 damit beginnen, master auf 9e5e6a4 zeigen zu lassen.
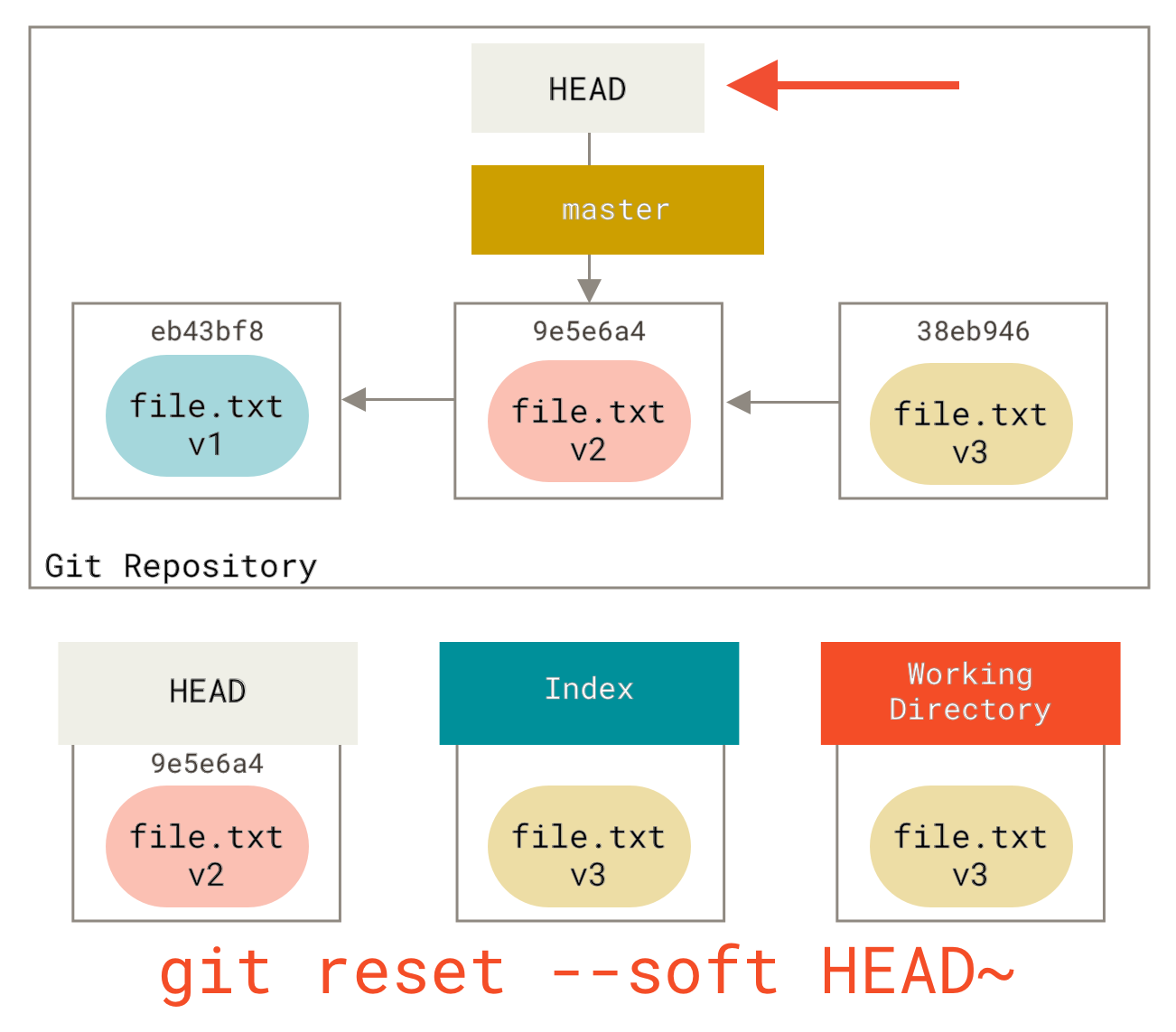
Unabhängig von der Form von reset mit einem Commit, das Sie aufrufen, ist dies das Erste, was es immer zu tun versucht. Mit reset --soft hört es einfach dort auf.
Nehmen Sie sich nun einen Moment Zeit, um dieses Diagramm anzusehen und zu erkennen, was passiert ist: Es hat im Wesentlichen den letzten git commit-Befehl rückgängig gemacht. Wenn Sie git commit ausführen, erstellt Git einen neuen Commit und bewegt den Branch, auf den HEAD zeigt, zu diesem neuen Commit. Wenn Sie reset zurück auf HEAD~ (den Elternknoten von HEAD) ausführen, bewegen Sie den Branch zurück an seinen ursprünglichen Ort, ohne den Index oder das Arbeitsverzeichnis zu ändern. Sie könnten dann den Index aktualisieren und erneut git commit ausführen, um das zu erreichen, was git commit --amend getan hätte (siehe Ändern des letzten Commits).
Schritt 2: Aktualisieren des Index (--mixed)
Beachten Sie, dass Sie, wenn Sie jetzt git status ausführen, in Grün den Unterschied zwischen dem Index und dem neuen HEAD sehen werden.
Das nächste, was reset tut, ist, den Index mit dem Inhalt des Snapshots zu aktualisieren, auf den HEAD jetzt zeigt.

Wenn Sie die Option --mixed angeben, stoppt reset an diesem Punkt. Dies ist auch der Standard, sodass, wenn Sie überhaupt keine Option angeben (in diesem Fall nur git reset HEAD~), der Befehl hier stoppt.
Nehmen Sie sich nun noch einen Moment Zeit, um dieses Diagramm anzusehen und zu erkennen, was passiert ist: Es hat Ihren letzten commit immer noch rückgängig gemacht, aber auch alles *un-gestaged*. Sie sind zu dem Zustand zurückgekehrt, bevor Sie alle Ihre git add- und git commit-Befehle ausgeführt haben.
Schritt 3: Aktualisieren des Arbeitsverzeichnisses (--hard)
Das Dritte, was reset tut, ist, das Arbeitsverzeichnis so aussehen zu lassen wie den Index. Wenn Sie die Option --hard verwenden, wird es bis zu dieser Stufe fortgesetzt.

Denken wir also darüber nach, was gerade passiert ist. Sie haben Ihren letzten Commit, die Befehle git add und git commit *sowie* all die Arbeit, die Sie in Ihrem Arbeitsverzeichnis geleistet haben, rückgängig gemacht.
Es ist wichtig zu beachten, dass dieses Flag (--hard) die einzige Möglichkeit ist, den Befehl reset gefährlich zu machen, und einer der wenigen Fälle, in denen Git tatsächlich Daten zerstört. Jede andere Verwendung von reset kann ziemlich leicht rückgängig gemacht werden, aber die Option --hard nicht, da sie Dateien im Arbeitsverzeichnis zwangsweise überschreibt. In diesem speziellen Fall haben wir immer noch die Version **v3** unserer Datei in einem Commit in unserer Git-DB und könnten sie durch Betrachten unseres reflog zurückholen. Aber wenn wir sie nicht committet hätten, hätte Git die Datei trotzdem überschrieben und sie wäre nicht wiederherstellbar.
Zusammenfassung
Der Befehl reset überschreibt diese drei Bäume in einer bestimmten Reihenfolge und stoppt, wenn Sie es ihm sagen
-
Bewegen Sie den Branch, auf den HEAD zeigt (stoppen Sie hier, wenn
--soft). -
Lassen Sie den Index wie HEAD aussehen (stoppen Sie hier, es sei denn,
--hard). -
Lassen Sie das Arbeitsverzeichnis wie den Index aussehen.
Reset mit einem Pfad
Das deckt das Verhalten von reset in seiner Grundform ab, aber Sie können ihm auch einen Pfad angeben, auf den er angewendet werden soll. Wenn Sie einen Pfad angeben, überspringt reset Schritt 1 und beschränkt die übrigen Aktionen auf eine bestimmte Datei oder eine Gruppe von Dateien. Das ergibt eigentlich Sinn – HEAD ist nur ein Zeiger, und Sie können nicht auf einen Teil eines Commits und auf einen Teil eines anderen zeigen. Aber der Index und das Arbeitsverzeichnis *können* teilweise aktualisiert werden, so dass reset mit den Schritten 2 und 3 fortfährt.
Nehmen wir also an, wir führen git reset file.txt aus. Diese Form (da Sie weder einen Commit-SHA-1 oder Branch angegeben noch --soft oder --hard angegeben haben) ist eine Kurzform für git reset --mixed HEAD file.txt, was Folgendes bewirkt:
-
Bewegen Sie den Branch, auf den HEAD zeigt (übersprungen).
-
Lassen Sie den Index wie HEAD aussehen (hier stoppen).
Es kopiert also im Wesentlichen file.txt von HEAD in den Index.
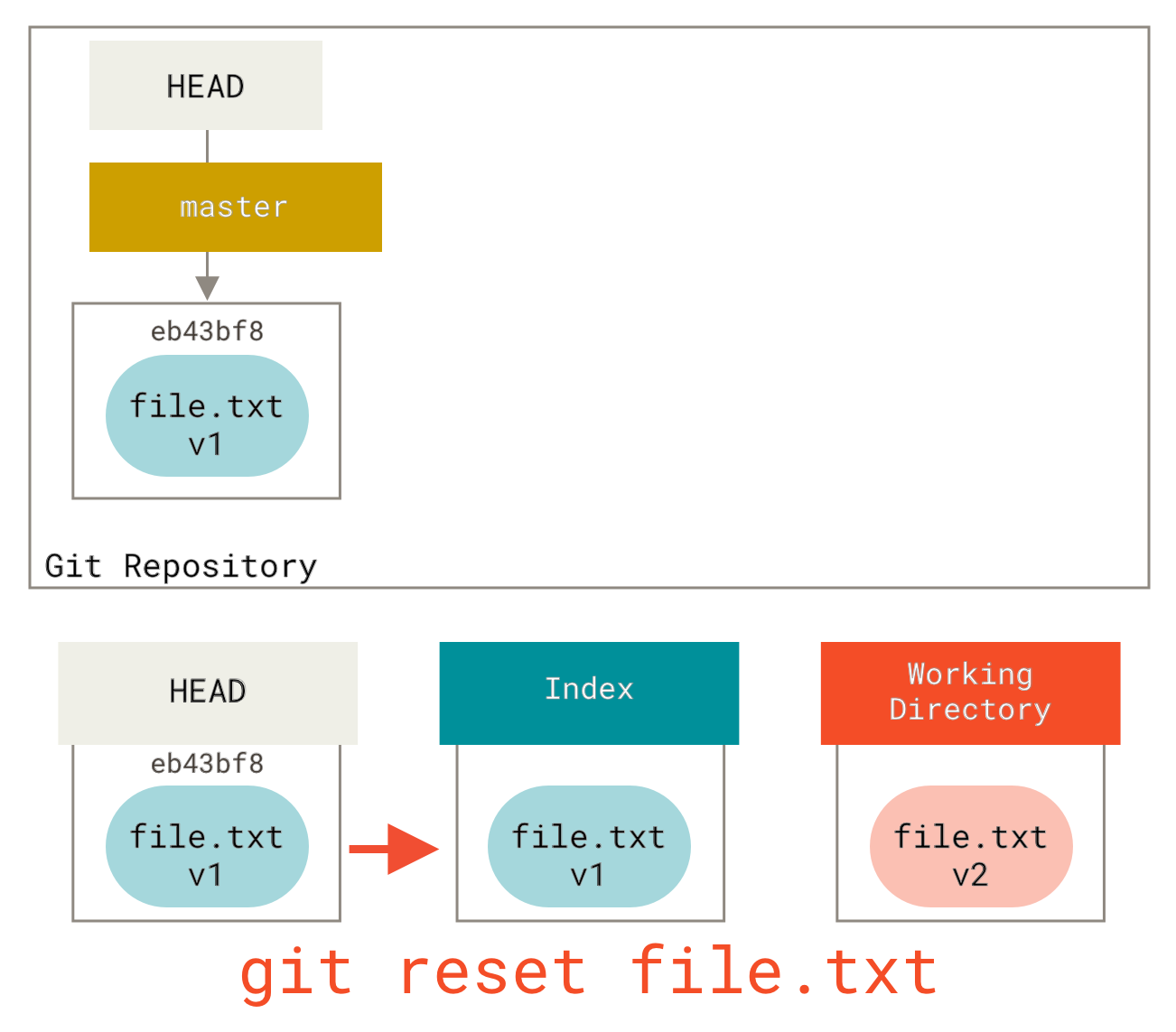
Dies hat den praktischen Effekt, die Datei *un-stagen*. Wenn wir uns das Diagramm für diesen Befehl ansehen und darüber nachdenken, was git add tut, sind sie exakte Gegensätze.
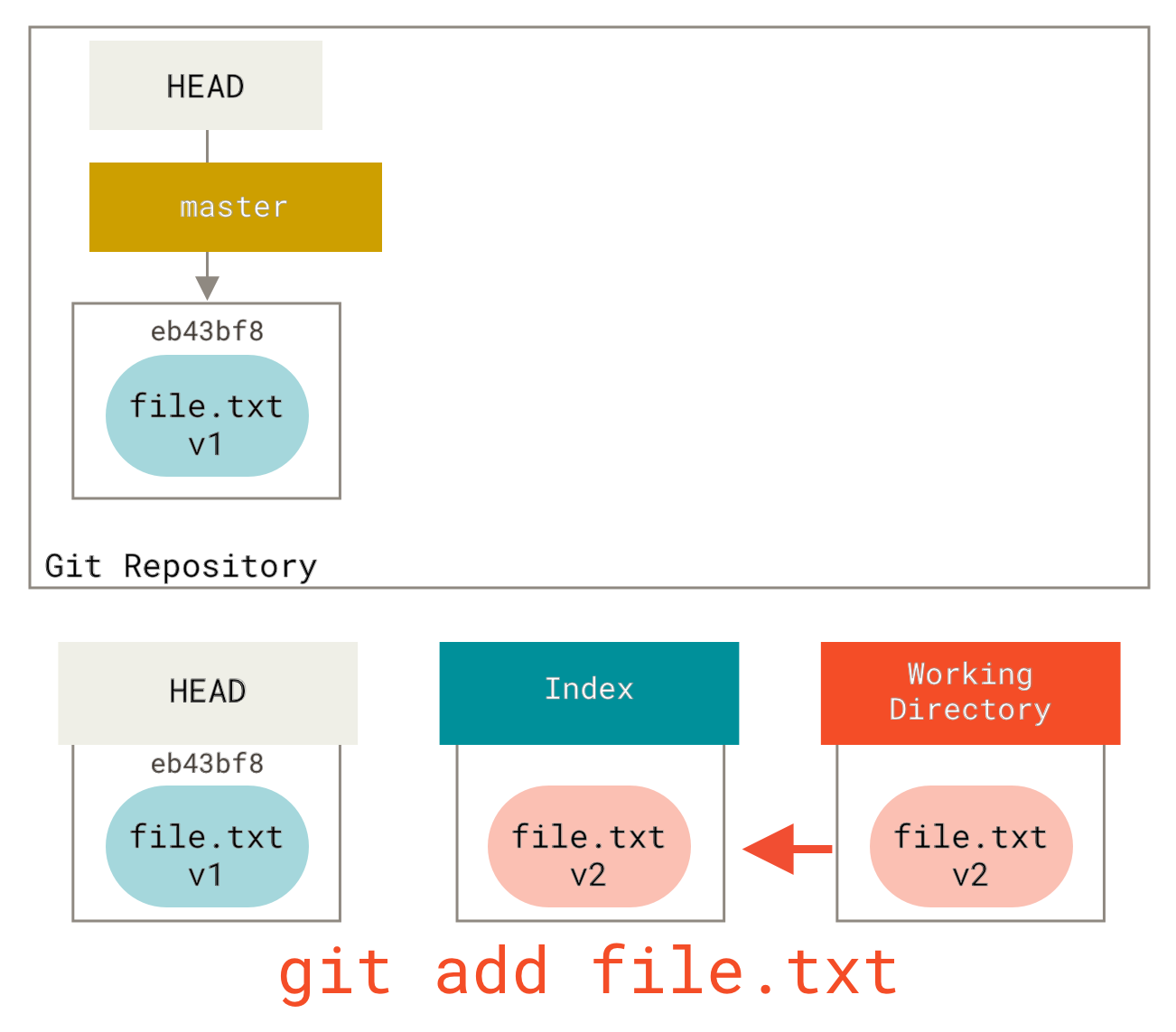
Deshalb schlägt die Ausgabe des Befehls git status vor, dass Sie dies ausführen, um eine Datei zu un-stagen (siehe Entfernen einer gestagten Datei für mehr dazu).
Wir könnten Git auch einfach nicht davon ausgehen lassen, dass wir "die Daten von HEAD ziehen" meinten, indem wir einen bestimmten Commit angeben, von dem wir diese Dateiversion ziehen wollen. Wir würden einfach etwas wie git reset eb43bf file.txt ausführen.
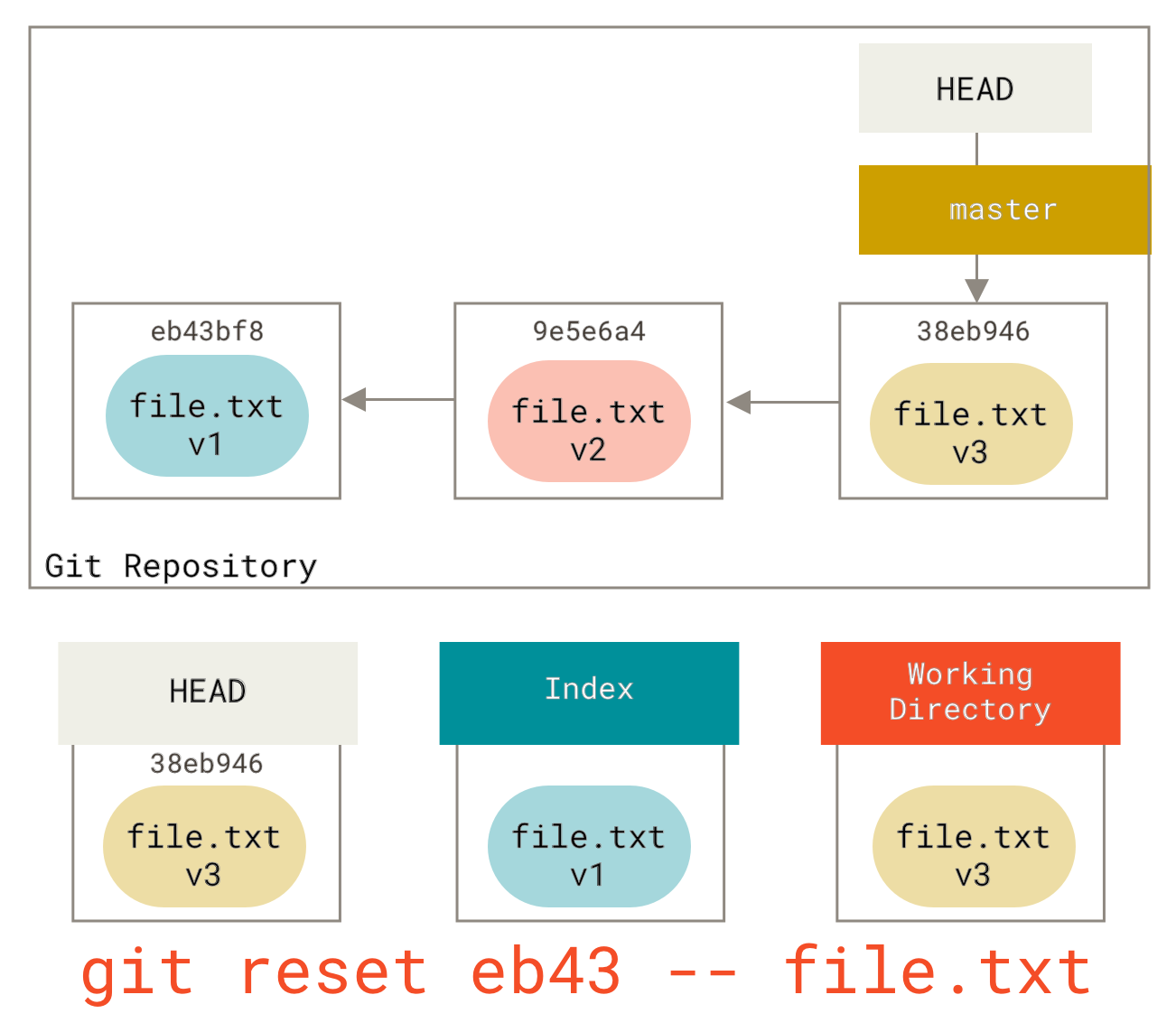
Dies bewirkt im Wesentlichen dasselbe, als hätten wir den Inhalt der Datei in der Arbeitskopie auf **v1** zurückgesetzt, git add darauf ausgeführt und sie dann wieder auf **v3** zurückgesetzt (ohne tatsächlich all diese Schritte zu durchlaufen). Wenn wir jetzt git commit ausführen, wird eine Änderung aufgezeichnet, die diese Datei auf **v1** zurücksetzt, obwohl wir sie nie wieder in unserem Arbeitsverzeichnis hatten.
Es ist auch interessant zu beachten, dass der Befehl reset, wie git add, eine Option --patch akzeptiert, um Inhalte Hunk für Hunk zu un-stagen. Sie können also Inhalte selektiv un-stagen oder zurücksetzen.
Squashing
Betrachten wir, wie man mit dieser neu gewonnenen Macht etwas Interessantes tun kann – Commits zusammenfassen (Squashing).
Nehmen wir an, Sie haben eine Reihe von Commits mit Nachrichten wie "Ups.", "WIP" und "Habe diese Datei vergessen". Sie können reset verwenden, um sie schnell und einfach in einen einzigen Commit zusammenzufassen, der Sie wirklich schlau aussehen lässt. Commits zusammenfassen zeigt eine andere Möglichkeit, dies zu tun, aber in diesem Beispiel ist es einfacher, reset zu verwenden.
Sagen wir, Sie haben ein Projekt, bei dem der erste Commit eine Datei hat, der zweite Commit eine neue Datei hinzufügt und die erste ändert, und der dritte Commit die erste Datei erneut ändert. Der zweite Commit war ein Arbeitsentwurf und Sie möchten ihn zusammenfassen.
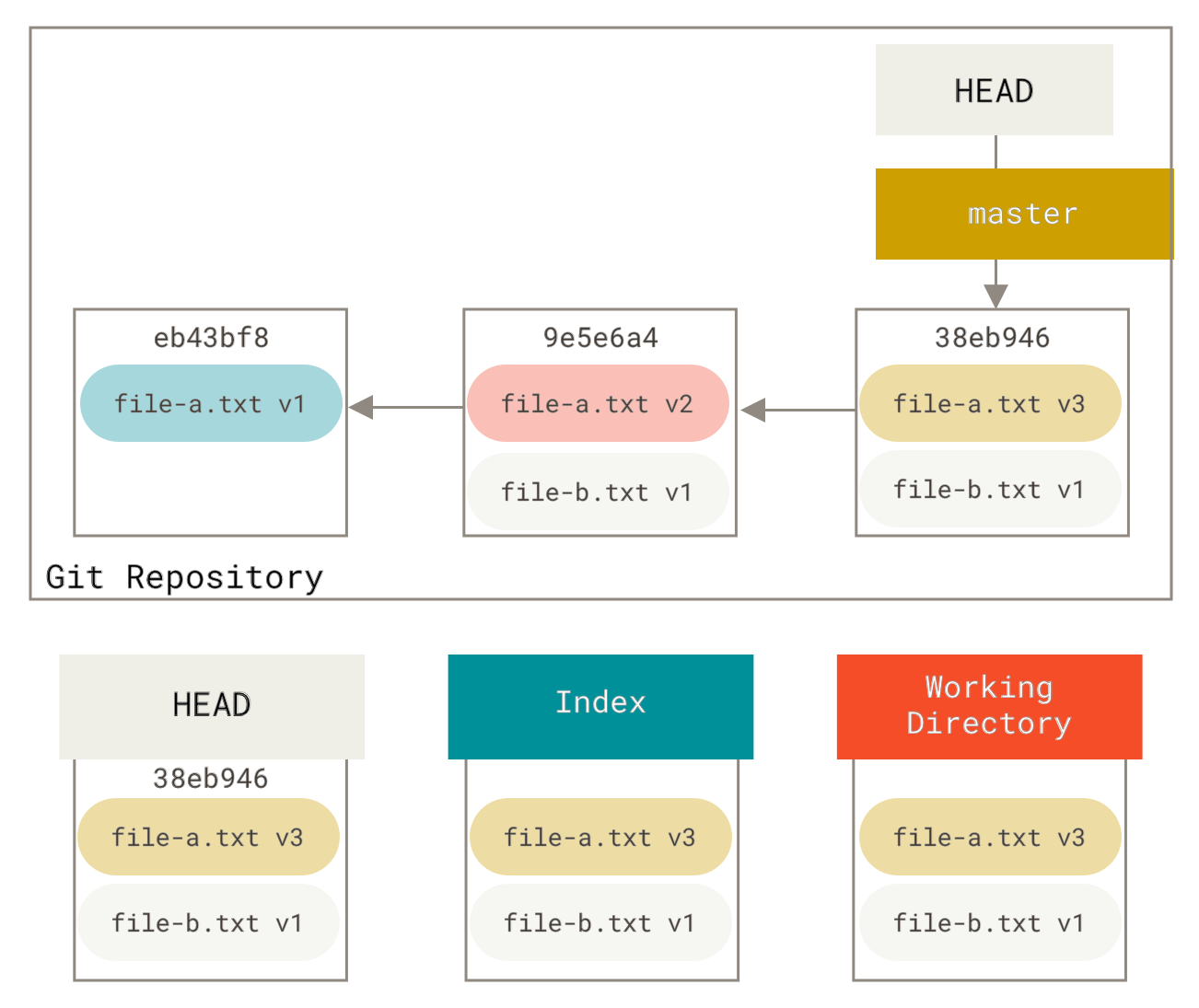
Sie können git reset --soft HEAD~2 ausführen, um den HEAD-Branch zu einem älteren Commit zurückzubewegen (dem aktuellsten Commit, den Sie behalten möchten)
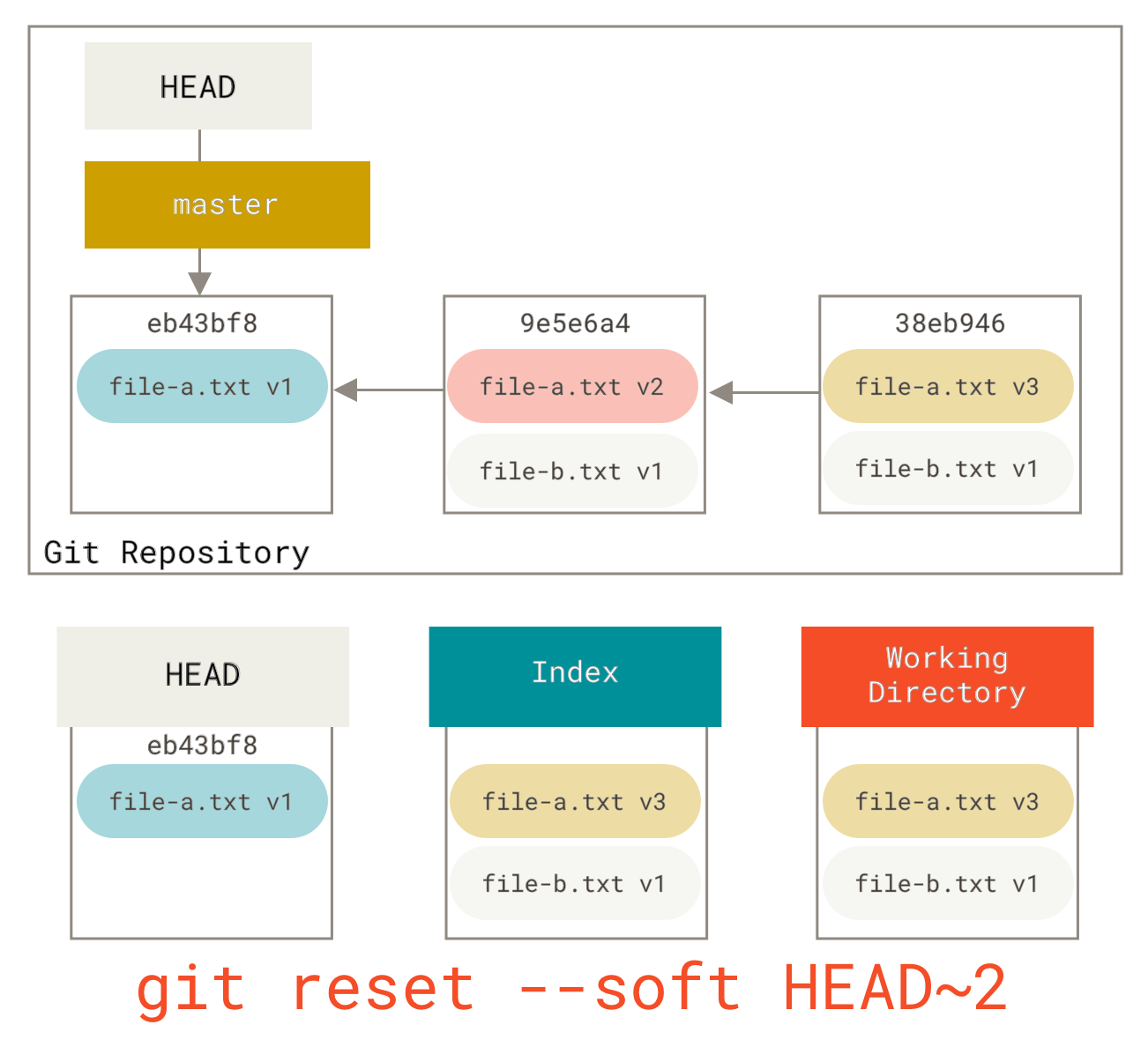
Und dann einfach erneut git commit ausführen
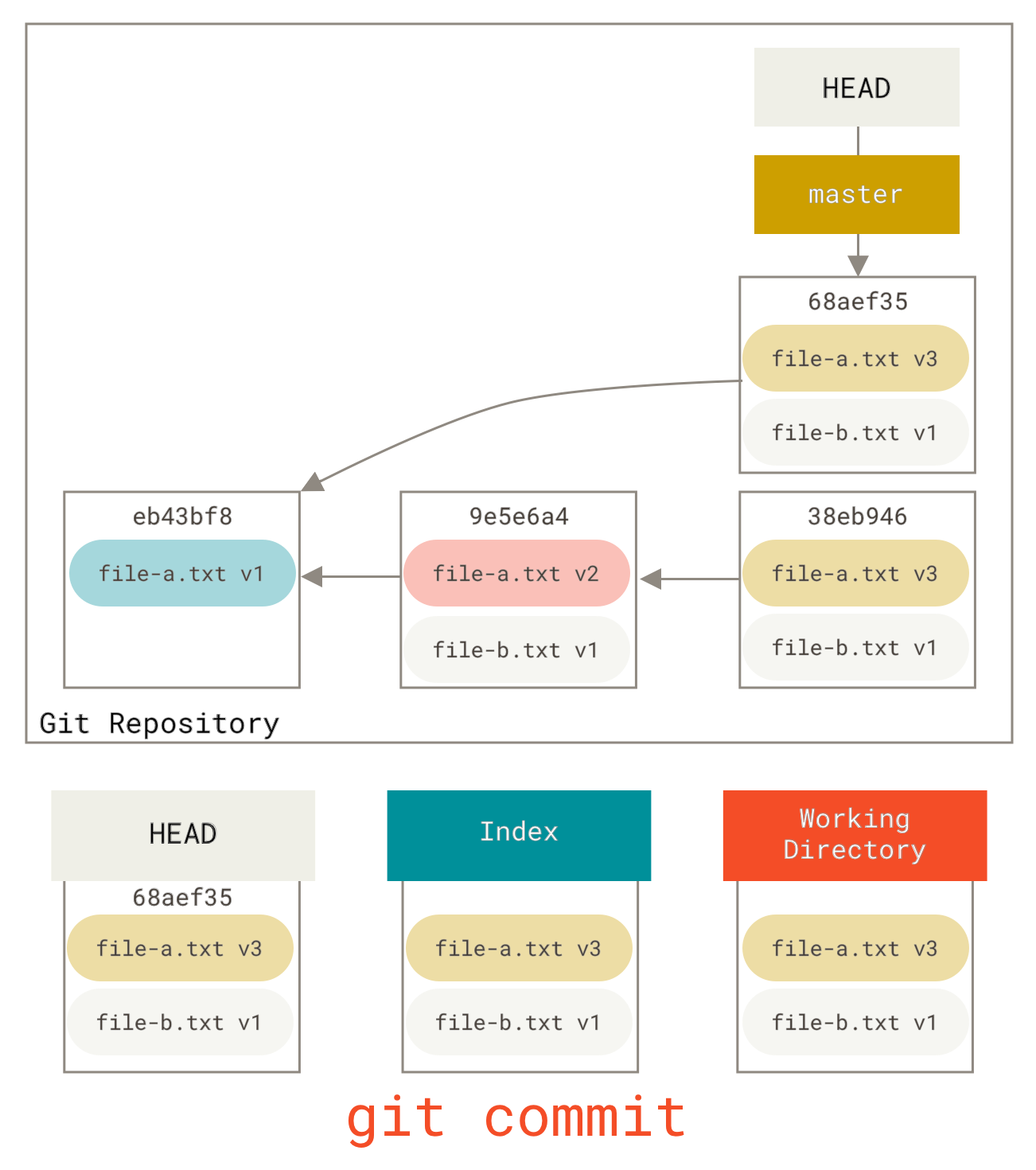
Jetzt sehen Sie, dass Ihre erreichbare Historie, die Historie, die Sie pushen würden, jetzt so aussieht, als hätten Sie einen Commit mit file-a.txt **v1** gehabt, dann einen zweiten, der sowohl file-a.txt zu **v3** geändert als auch file-b.txt hinzugefügt hat. Der Commit mit der **v2**-Version der Datei ist nicht mehr in der Historie.
Schauen wir uns das an
Schließlich fragen Sie sich vielleicht, was der Unterschied zwischen checkout und reset ist. Wie reset manipuliert checkout die drei Bäume, und es verhält sich etwas anders, je nachdem, ob Sie dem Befehl einen Dateipfad geben oder nicht.
Ohne Pfade
Das Ausführen von git checkout [branch] ist ziemlich ähnlich dem Ausführen von git reset --hard [branch], da es alle drei Bäume aktualisiert, damit sie wie [branch] aussehen, aber es gibt zwei wichtige Unterschiede.
Erstens, im Gegensatz zu reset --hard ist checkout sicher für das Arbeitsverzeichnis; es prüft, ob es keine Dateien mit Änderungen wegbläst. Tatsächlich ist es etwas intelligenter – es versucht, eine triviale Zusammenführung im Arbeitsverzeichnis durchzuführen, sodass alle Dateien, die Sie *nicht* geändert haben, aktualisiert werden. reset --hard hingegen ersetzt einfach alles pauschal, ohne zu prüfen.
Der zweite wichtige Unterschied ist, wie checkout HEAD aktualisiert. Während reset den Branch bewegt, auf den HEAD zeigt, bewegt checkout HEAD selbst, um auf einen anderen Branch zu zeigen.
Zum Beispiel: Nehmen wir an, wir haben die Branches master und develop, die auf verschiedene Commits zeigen, und wir befinden uns gerade auf develop (also zeigt HEAD darauf). Wenn wir git reset master ausführen, wird develop selbst nun auf denselben Commit zeigen wie master. Wenn wir stattdessen git checkout master ausführen, bewegt sich develop nicht, sondern HEAD selbst bewegt sich. HEAD wird nun auf master zeigen.
Also, in beiden Fällen bewegen wir HEAD, um auf Commit A zu zeigen, aber *wie* wir das tun, ist sehr unterschiedlich. reset bewegt den Branch, auf den HEAD zeigt, checkout bewegt HEAD selbst.
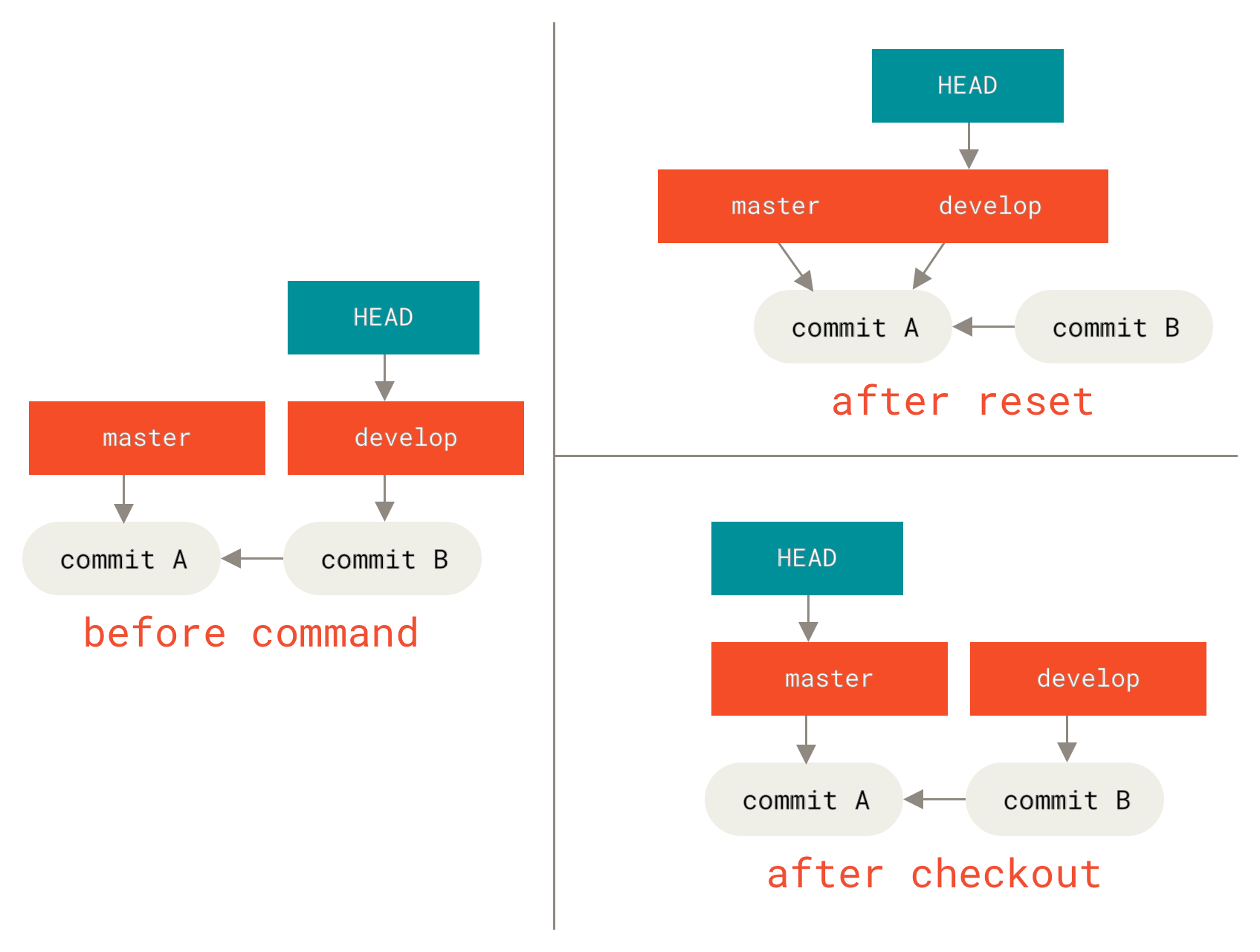
git checkout und git resetMit Pfaden
Die andere Möglichkeit, checkout auszuführen, ist mit einem Dateipfad, der, ähnlich wie reset, HEAD nicht bewegt. Es ist genau wie git reset [branch] file, da es den Index mit dieser Datei in diesem Commit aktualisiert, aber es überschreibt auch die Datei im Arbeitsverzeichnis. Es wäre genau wie git reset --hard [branch] file (wenn reset das zulassen würde) – es ist nicht sicher für das Arbeitsverzeichnis und bewegt HEAD nicht.
Ebenso wie git reset und git add akzeptiert checkout die Option --patch, um das selektive Zurücksetzen von Dateiinhalten Hunk für Hunk zu ermöglichen.
Zusammenfassung
Hoffentlich verstehen Sie nun den Befehl reset besser und fühlen sich damit wohler, sind aber wahrscheinlich immer noch etwas verwirrt, wie genau er sich von checkout unterscheidet und können sich unmöglich alle Regeln der verschiedenen Aufrufe merken.
Hier ist eine Spickzettel, welche Befehle welche Bäume beeinflussen. Die Spalte "HEAD" liest "REF", wenn der Befehl die Referenz (Branch) bewegt, auf die HEAD zeigt, und "HEAD", wenn er HEAD selbst bewegt. Achten Sie besonders auf die Spalte "WD Safe?" – wenn dort **NEIN** steht, überlegen Sie kurz, bevor Sie diesen Befehl ausführen.
| HEAD | Index | Arbeitsverzeichnis | WD Sicher? | |
|---|---|---|---|---|
Commit-Ebene |
||||
|
REF |
NEIN |
NEIN |
JA |
|
REF |
JA |
NEIN |
JA |
|
REF |
JA |
JA |
NEIN |
|
HEAD |
JA |
JA |
JA |
Dateiebene |
||||
|
NEIN |
JA |
NEIN |
JA |
|
NEIN |
JA |
JA |
NEIN |